The post <br />Verbs, nouns and kanban board structure appeared first on This view of flow management....
]]>I have often been called upon to help organizations that have gotten off to a bad start in using kanban. Often, the team lack understanding of the scope of work items and the definitions of workflows. The kanban board structure suffers heavily. What approach have I found useful in making sense of these interrelated concepts? How can such easy more easily improve the kanban board structure?
The Existing Situation
Too often, the existing situation reflects more of a cargo cult approach to managing the flow of work. The work items consist of a hodge-podge of all sorts of work with all sorts of scopes. Those scopes range from short meetings to months-long projects. What do I often see when the workflows have more detail than To Do / Doing / Done? In such cases, the columns of the board often consist of an incoherent mixture of high-level tasks, minor details, milestones and queues. The cards on the board, too, reflect a lack of effective policies defining card scope.
Card and Column Redundancy
Some cards are redundant with the workflow columns. For example, there might be a column labeled Review the document and, sure enough, there is also a card entitled Review the document. The breadth of the work varies from large projects to minor activities, such as attending a short coordination meeting, and everything in between.
Visualize all your work?
Such situations often exist because the team had been advised that all of its work should appear on a kanban board. While the team should indeed start to make visible all its work, doing so without any guidance or policies is not a sustainable practice. Thus, seeing cards of all sorts might be normal during the first few weeks that a team works with a board. But the team should quickly evolve from that state. Otherwise, it is not likely to get much benefit from either the board itself or from the kanban method. At worst, the board is apt to die out, being considered as administrative overhead with little added value.
Making sense of the cards and columns
Teams in such situations need quick and simple remedial actions to start making sense of the kanban board. They need clear and easily understandable principles to apply to the use of the board. Only then can teams start using their boards as fundamental tools for the continual improvement of the flow of work.
The analogy of language syntax1 helps to provide this clarity. At the simplest level, I have found it useful to think of the columns on the board as verbs and the cards as nouns.
Columns are verbs
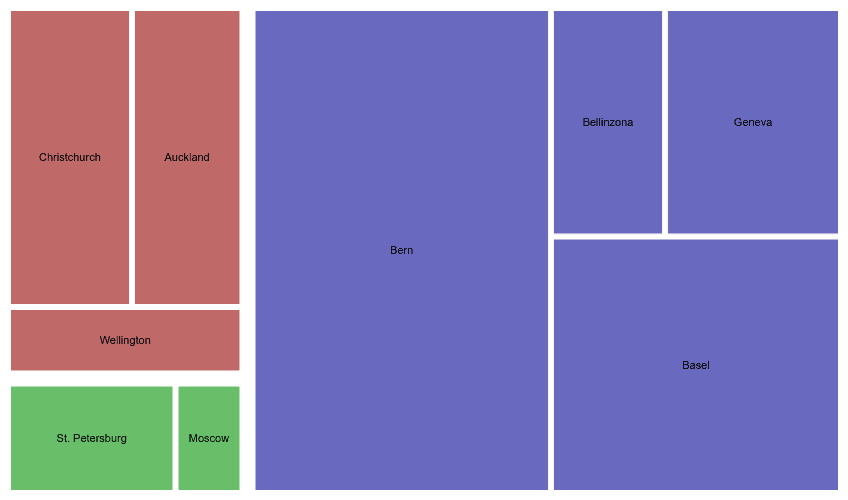
Let’s take a simple example. Suppose a team’s value stream consists of analyzing, building and testing work items. The columns on the In Progress portion of the board should all be labeled as verb phrases. Thus, the column labels might be Analyze, Build and Test.
Avoid noun phrases
Avoid noun phrases, such as Analysis, Construction and Testing, to label the columns. Noun phrases lead to confusion between the action performed and the object upon which that action acts.
Avoid adjectives and adverbs
Avoid adjectival or adverbial column labels, which tend to reflect the status of work rather than the activity the team performs. Work status should be obvious based on the position of the work item in the relevant column. Trying to express work status in another way is supererogatory. Labeling columns, too, with status information is redundant and leads to confusion about where to place a card. You might object that the classic column names Ready and Done do not obey this rule. I discuss that issue below.
Labeling Queues
How would we label the columns used to model queues? After all, by definition teams do not actively operate on work in queues. There might be a tendency to label queues with adjectives. Thus, you might see something like Doing Analysis followed by a queue called Analysis Done. I would recommend rather to maintain verb phrases. Thus, the columns would be Analyze and then Wait for Building (assuming the following column is Build). Similarly, we would see Build and then Wait for Testing. Using verb phrases for queues renders clearly why a work item is in the column and what is expected to happen next.
Cards are Nouns
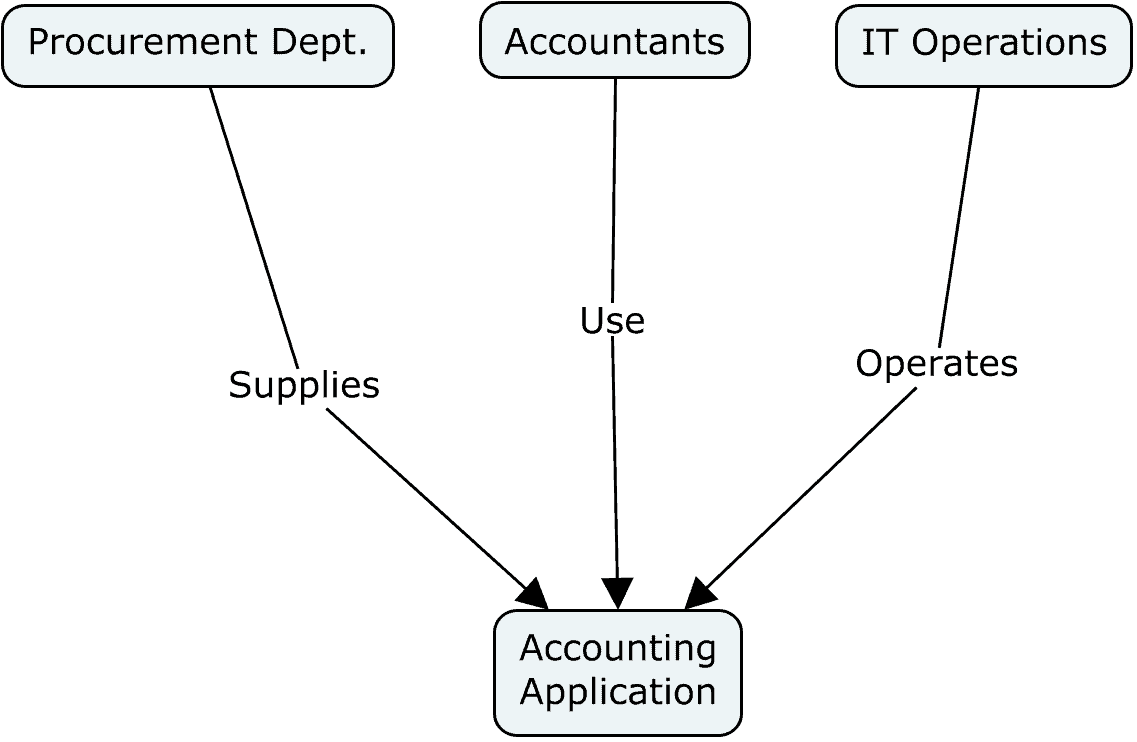
If columns are verbs, then the work items associated with cards are nouns. More particularly, they are the objects of the verbs. If, for example, a column is labeled with the verb Analyze, we need to ask the question, “Analyze what?” The title of a card provides the answer to that question. That same card title answers the questions, “What is waiting for building?” “What is being tested?” and so forth.
Suppose the team does marketing work. It defines a value streams for creating and executing a marketing campaign. Each marketing campaign (a noun) would have its own card. Suppose the team is managing the on-boarding of a new employee. Each new employee would have her or his own card. Suppose a pharmaceutical team manages a clinical trial phase. Each deliverable in the phase would have a corresponding card. Suppose a finance team is preparing a quarterly budget update. Each budget reforecast would have its own card, and so forth.
Nouns, Verbs and Value Streams
Using nouns and verbs as described above makes it much easier to think of a workflow or process as a value stream. The noun is the bearer of value. It is the noun whose value is increased incrementally as it passes through the value stream. In the pharmaceutics example, each column of the clinical trial phase leads to a better estimation of the safety and effectiveness of the drug. In the financial example, each column makes the budget reforecast more likely to be accurate. In the marketing example, each column brings the campaign closer to prospective customer apt to buy the company’s product.
The verbs are the successive transformations of the noun that progressively add value. When thinking in such terms, many of the problems to which I alluded above would readily disappear. A card with a label such as “Coordination meeting” would make no sense. One does not “analyze” a coordination meeting as part of the normal workflow (unless that is a feedback loop/retrospective type of workflow). One does not “test” a coordination meeting, etc. Since such activities as coordination are not, by definition, value-adding activities, they should not appear as In Progress columns on the board.
Subjects of the Verbs
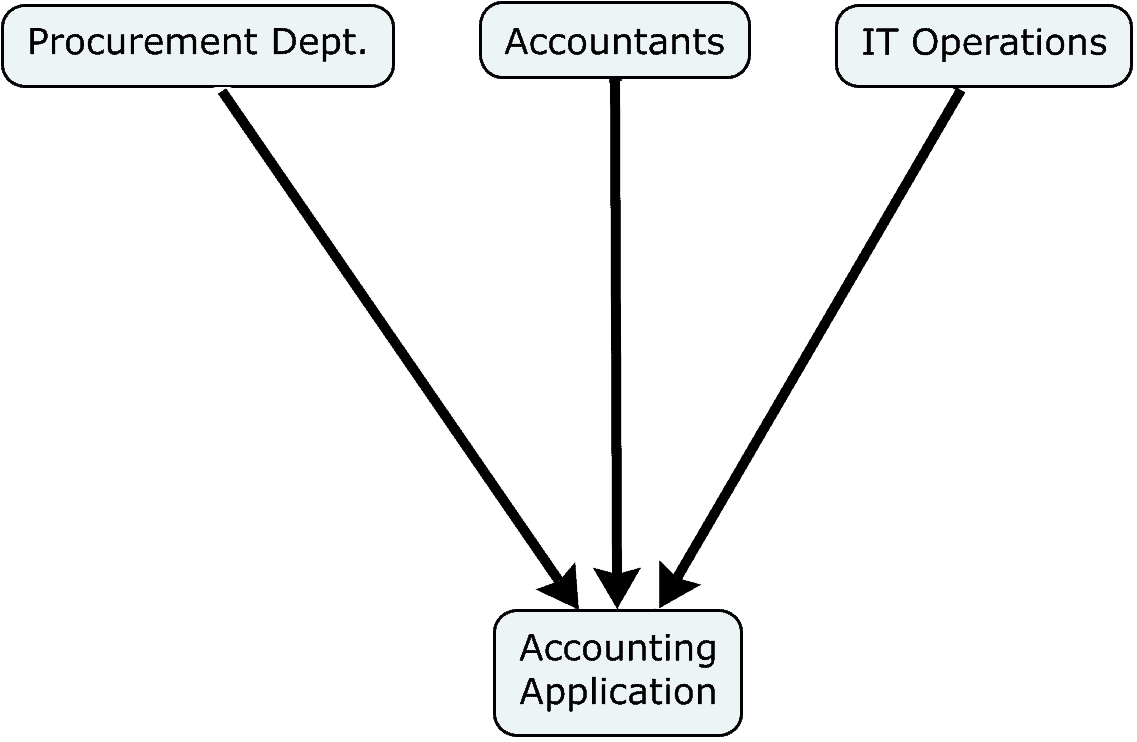
Continuing with the syntactical analogy, what would the subjects of the verbs be? Clearly, the they are the actors performing the value-adding actions that correspond to each column.
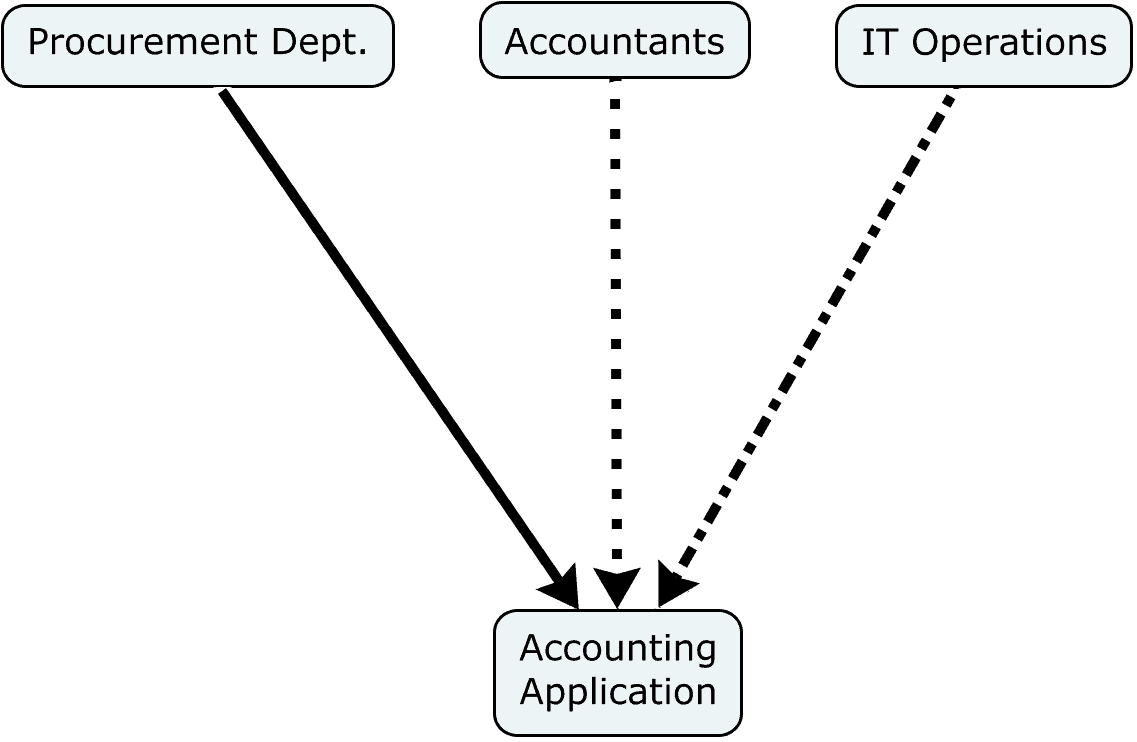
These subjects, or actors, are typically visualized as attributes of the individual cards, not as attributes of columns. Why is this so? The simple answer is that making them card attributes considerably enhances the flexibility and adaptability of the board. But let’s take a closer look.
Generalists and Specialists
Suppose a team consists of specialists, where each action or column is performed by a distinct function. It might make sense to display the name of that function as the subject of the verb describing the column’s activity. Suppose a team working on a drug’s clinical trial consists of statisticians, programmers, medical writers and data managers. One might imagine that a column called Analyze the Probability might be more precisely labeled as Statistician Analyzes the Probability. Similarly, a column labeled Write the Report might instead be labeled as Medical Writer Writes the Report.
That approach makes little sense if the team consists of generalists, where many team members are capable of performing many different types of work. Indeed, much of the early development of kanban for knowledge work concerned such teams. As a result, the inclusion of function names as the subjects of column labels never gained traction.
Separation of Duties
In other cases, a team desires a separation of duties rather than being constrained by distinct technical expertise. In such cases, the team decides that the person performing one activity should be someone other than the person performing the previous activity. This approach could add value by avoiding many cognitive biases and by adding the thoughts and experiences of multiple people to the work item. It is also a common practice intended to improve information security
Thus, if you have as succeeding columns Build then Test, it might be desirable that the tester be someone other than the builder. In this case, the identity of the worker—rather than the worker’s function—is important. Normally, worker identity is an attribute of the individual work items, not of the columns.
The Backlog, Commitment and Done
- Better integration of a team’s value streams into the overall value chain
- Clarification of what should happen in transitioning from the backlog to In Progress
Value Stream Integration
When a board’s workflow starts with “Backlog” and ends with “Done”, the visual presentation gives the impression of the team’s work being isolated and independent of activities elsewhere in the organization. But such isolation is seldom the case. It smacks of edge-of-the-world, flat earth thinking. Rather, the object to which the value stream adds values is delivered to some customer, for the purpose of achieving certain outcomes.
gives the impression of the team’s work being isolated and independent of activities elsewhere in the organization. But such isolation is seldom the case. It smacks of edge-of-the-world, flat earth thinking. Rather, the object to which the value stream adds values is delivered to some customer, for the purpose of achieving certain outcomes.
As the value stream mapping exercise makes clear, it is of critical importance for a team to understand who are its suppliers (deliverers of input to the work) and customers (recipients of the output of the work). From the perspective of the enterprise, work is not “done” when it reaches the last column on the last kanban board. Rather, work is in a queue waiting for the next team or customer to make use of that work.
Consequently, it might make sense to rename a column from “Done” to “Wait for Team X to Handle” or something of the sort. This is particularly interesting if a team provides shared services, directing its output to various customers. Rather than a single “Done” column, the team might have multiple sub-columns for its output, depending on who should be receiving the output. A similar principle could be applied to the backlog.
Transitioning out of the Backlog
A backlog is not simply a queue in which work items passively await further handling. What is really happening to work items in a backlog? It makes sense to limit the non-value-adding effort to manage items in a backlog. There is nonetheless certain work to be done.
The first task is to decide to which backlog items the team should commit execution. The second task is to make more precise to what the team is committing. I intend to discuss this second task in a future article. In any case, it behooves the team to limit its effort in performing these tasks, given the risk that a work item might never go through the value stream and deliver some value.
How, then, might we label this column with a verb phrase, rather than as simply as Backlog? Perhaps a more expressive label would be Groom and Commit or Groom and Refine. What are the objects of this verb phrase? They are simply the requests made by customers to do work. As such you may even wish to label the column as Groom and Refine Customer Requests.
This label makes it clear that the team needs to remove from the column any work items it does not intend to perform and refine those work items as a prerequisite to committing to doing the work. It is useful, then, to move to a new column those work items to which the team has committed doing the work.
That new column is a true queue, in the sense that work items simply wait there. No work is done on them. Indeed, the moment any work is done on such a work item, the card should be moved to the first In Progress column. How might we label this column, rather than something like Ready? Following the verb phrase recommendation, perhaps we could label it Wait for Capacity to Handle. Once that capacity is available, the next work item is selected, based on whatever priority policy the team has defined.
Summary
By modeling the column labels and card scopes using a language syntax analogy, we can visualize more clearly how work progresses through a value stream. We have simple rules to help teams define workflow structures and the scopes of cards.
In summary, each column is labeled as a verb phrase. Each work item is labeled as a noun phrase. That noun phrase is syntactically the object of the verb phrases in the columns. In certain cases, especially when agility is not very important and teams are composed of specialists, columns may be labeled as sentence fragments, including the name of the function responsible for doing the work in that column. In such cases, the function name would be the subject of the verb.
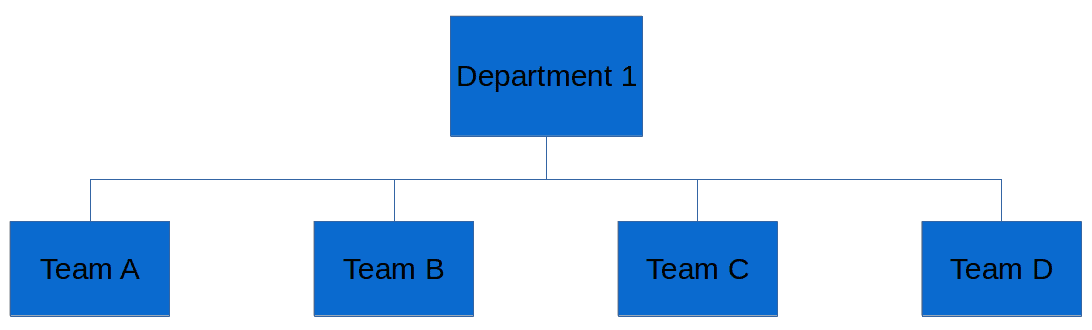
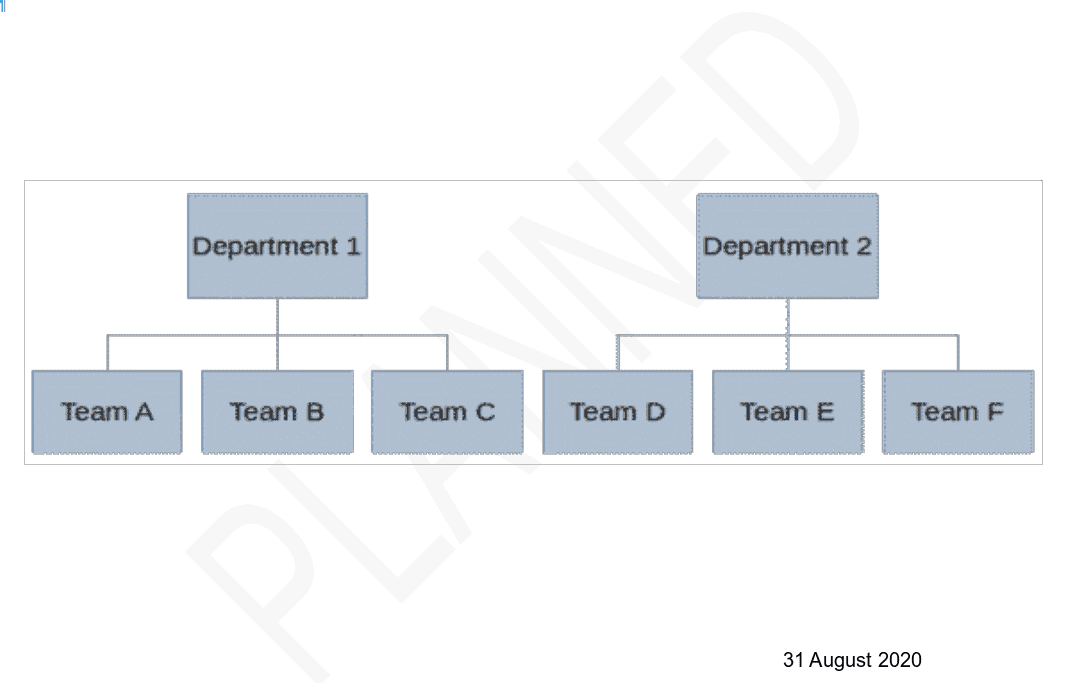
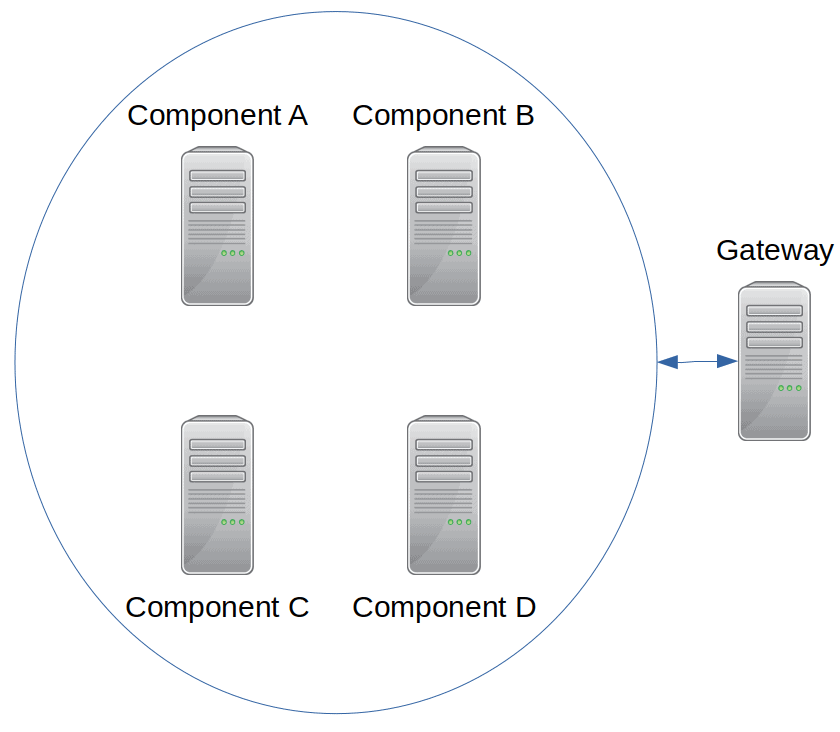
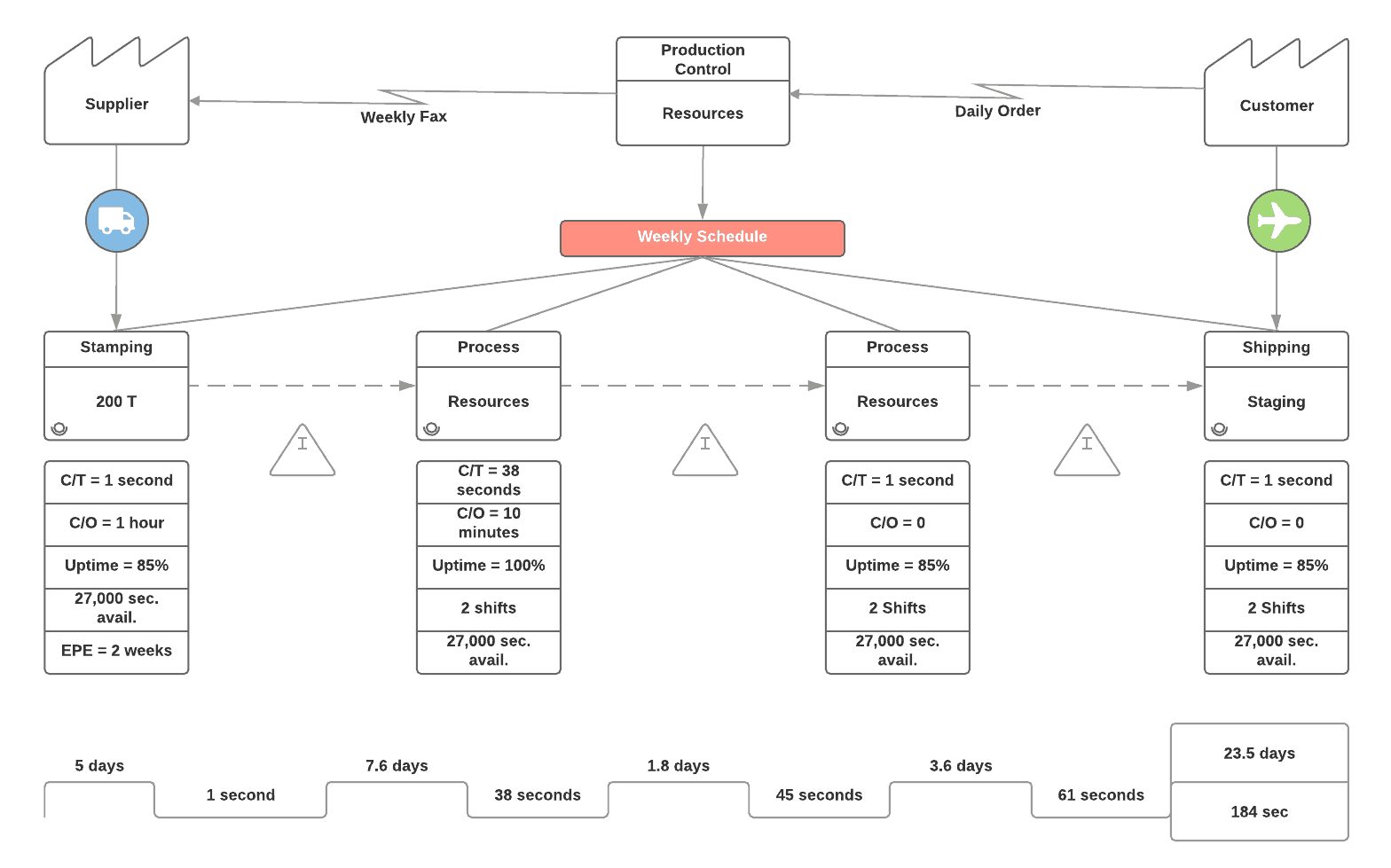
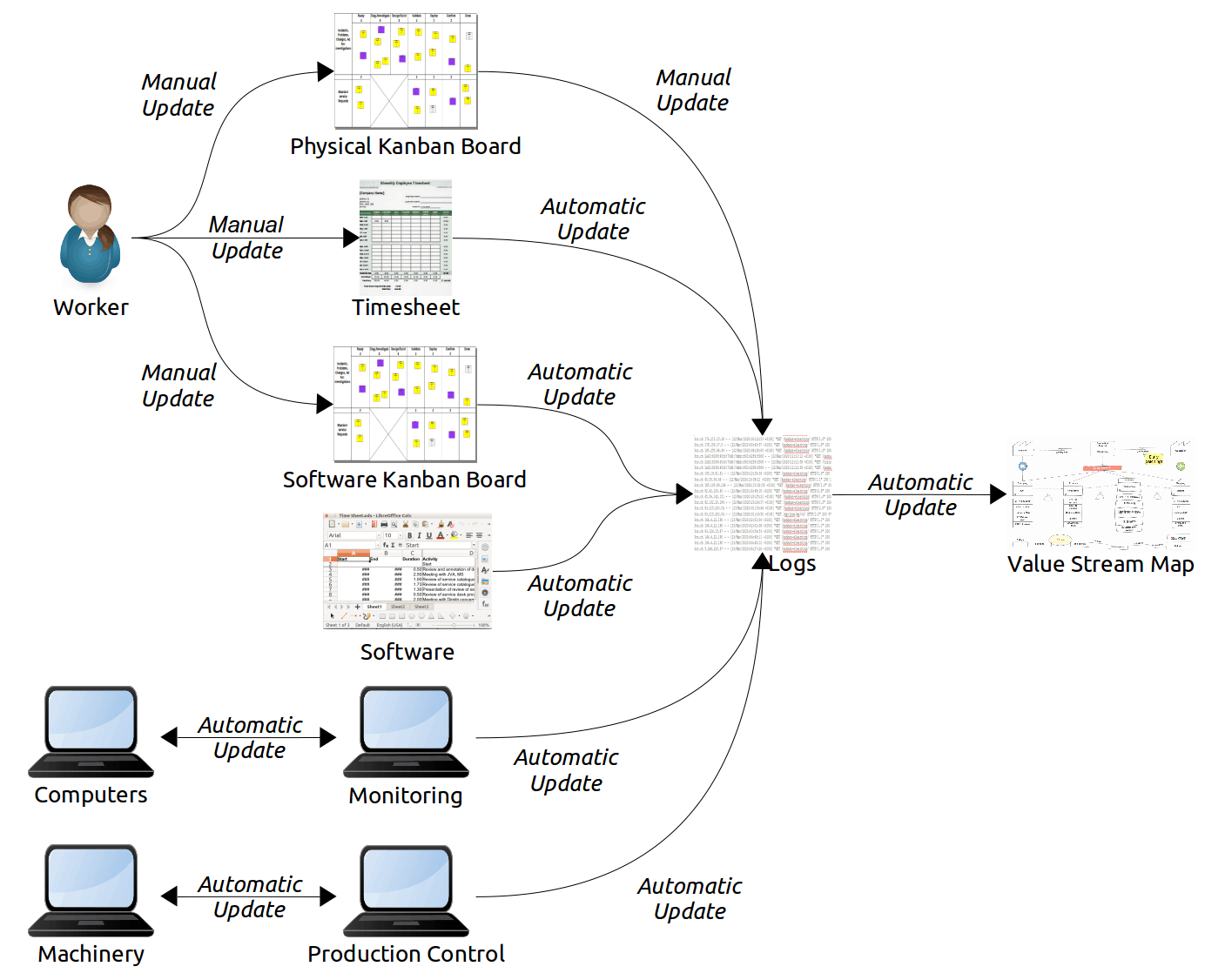
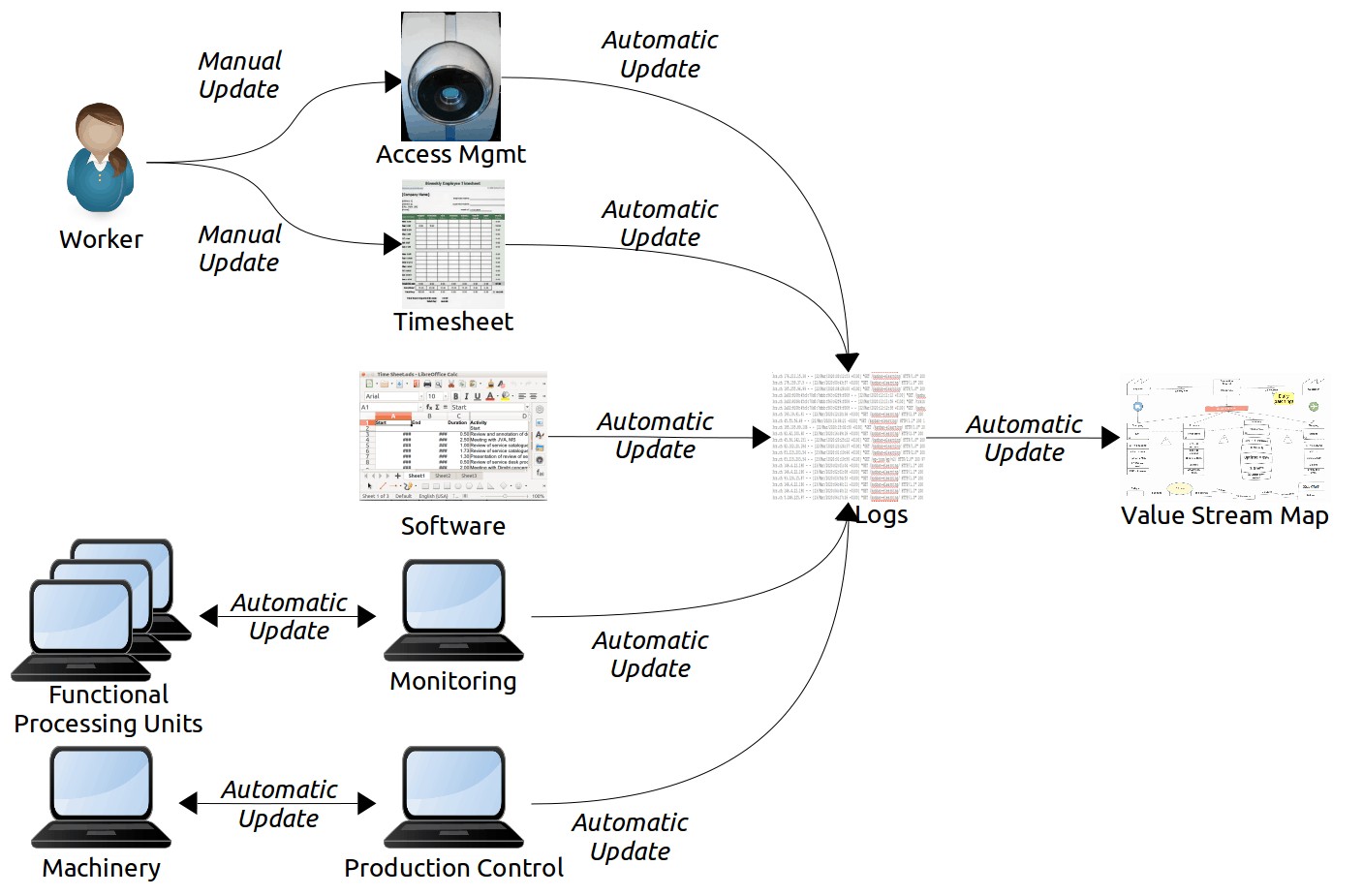
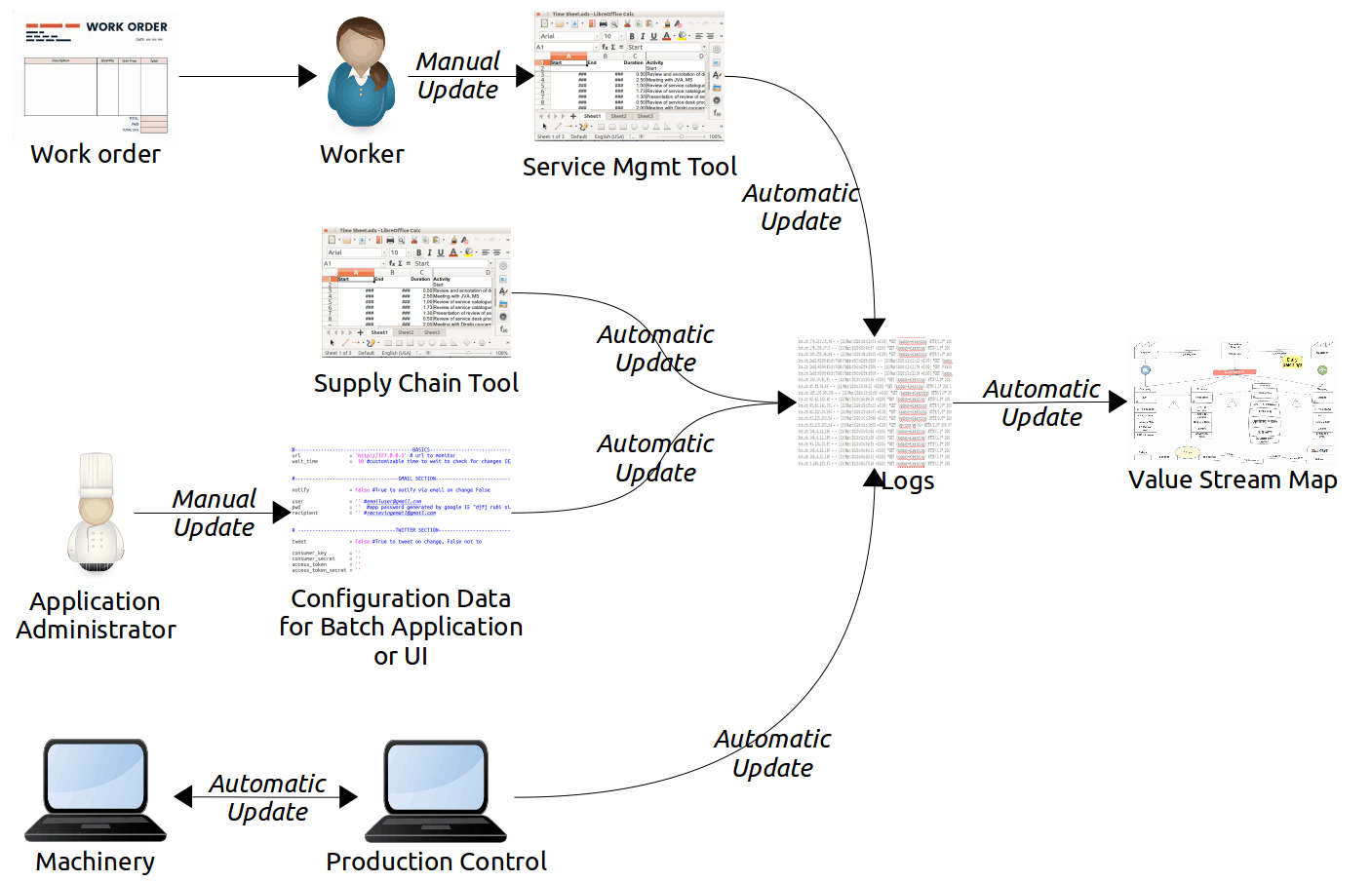
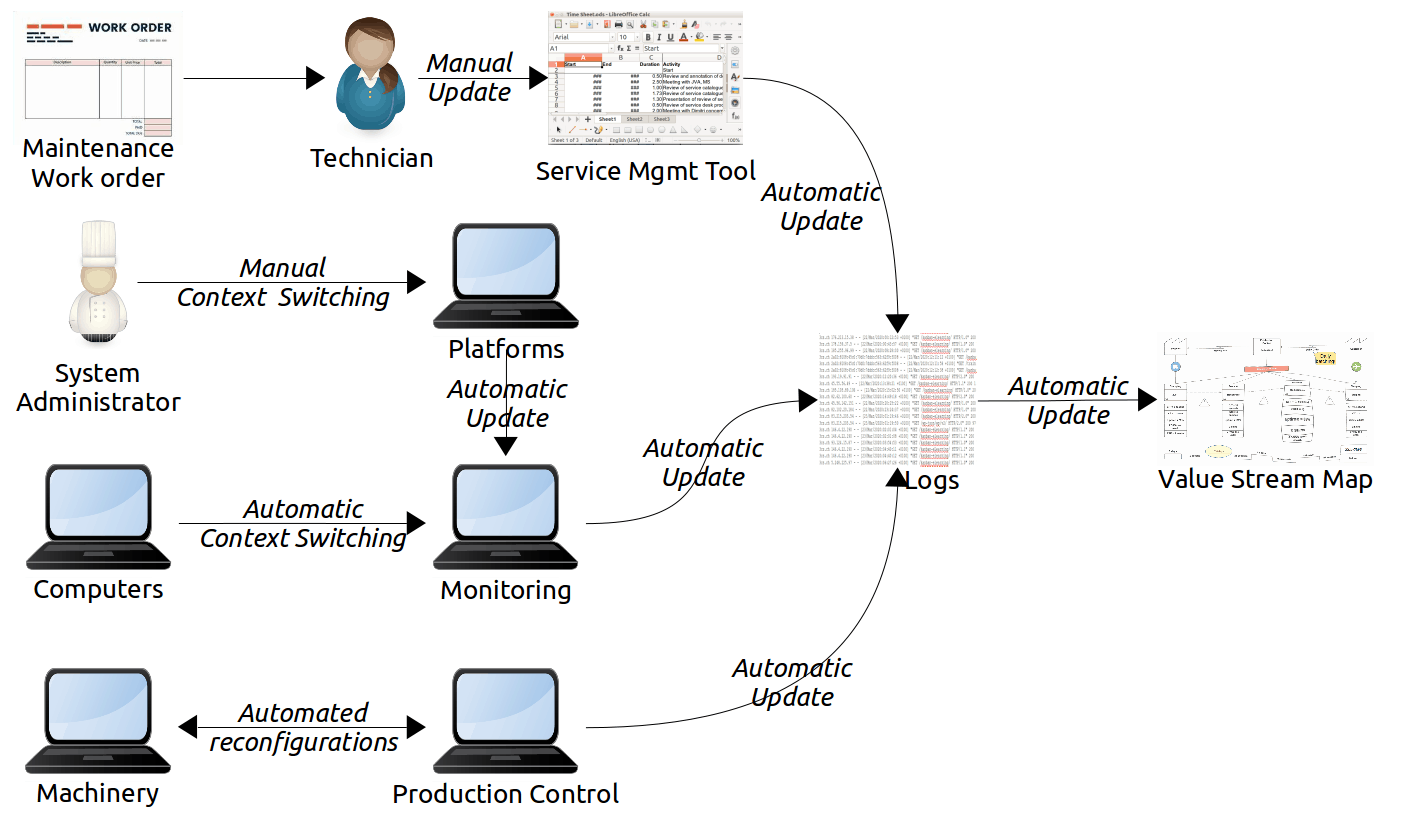
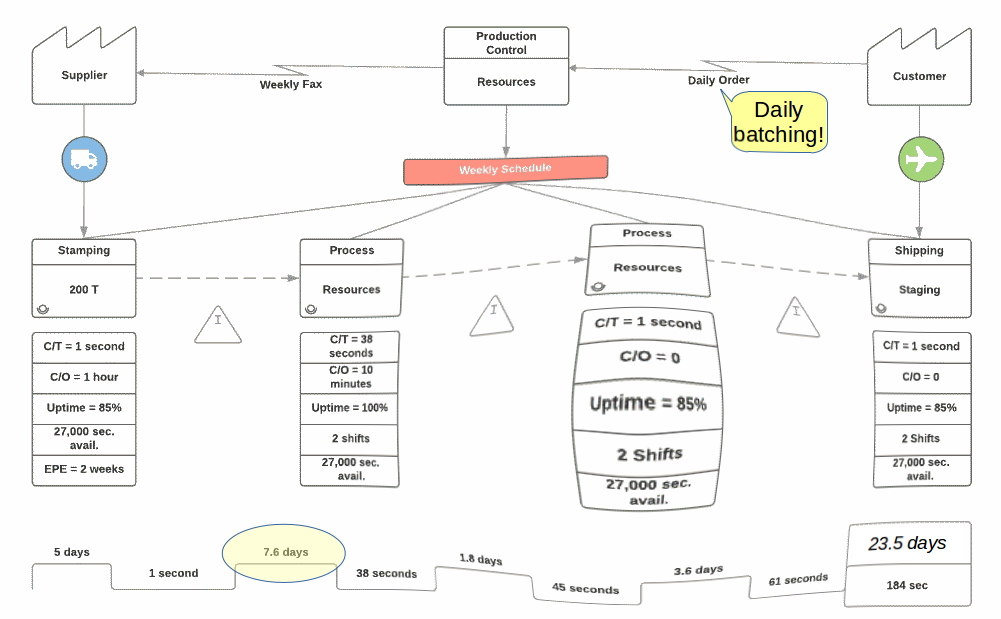
A simple example of a board applying these principles is illustrated below:

![]() The article Verbs, nouns and kanban board structure by Robert S. Falkowitz, including all its contents, is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
The article Verbs, nouns and kanban board structure by Robert S. Falkowitz, including all its contents, is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Notes:
1 I am aware that the analogy I make in this article to language syntax is meaningful only for many of the Indo-European, Hamito-Semitic and certain other languages. However, such concepts as verb objects and so forth might be meaningless in many other languages. I hope the linguists among the readers will excuse the ethnocentrism.
The post <br />Verbs, nouns and kanban board structure appeared first on This view of flow management....
]]>
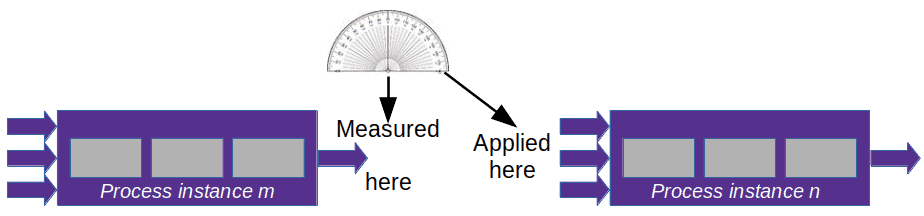
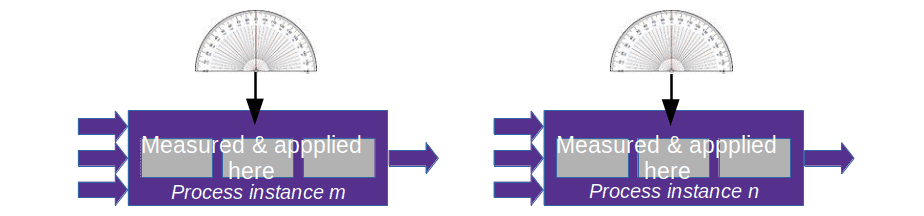
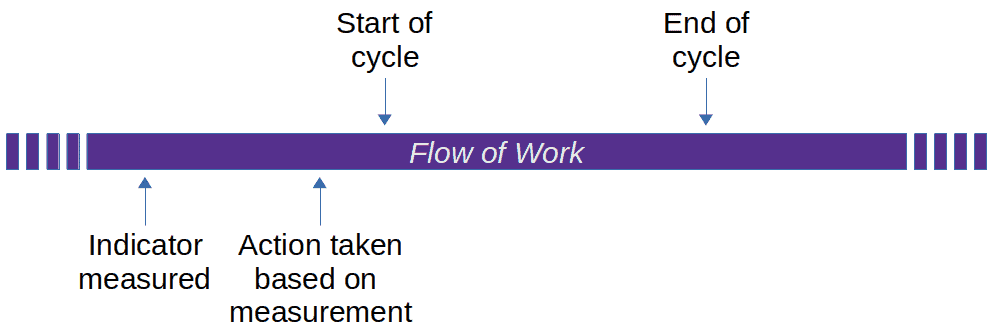
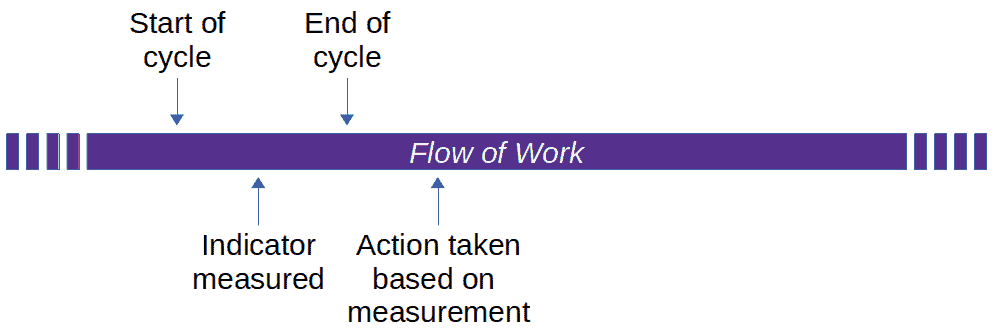
 Along indicator: While you enter the curve, your passenger shouts “Slow down!”. If your reaction time is sufficient and the road is not too slippery, you brake enough to safely negotiate the bend.
Along indicator: While you enter the curve, your passenger shouts “Slow down!”. If your reaction time is sufficient and the road is not too slippery, you brake enough to safely negotiate the bend. Lag indicator: The police report about yet another fatal accident at that bend concluded that the car was going too fast. As a result, they had a large sign erected near the start of the bend saying “DANGEROUS CURVE AHEAD. SLOW DOWN!” Alas, that sign will bring neither the driver nor the passenger back to life.
Lag indicator: The police report about yet another fatal accident at that bend concluded that the car was going too fast. As a result, they had a large sign erected near the start of the bend saying “DANGEROUS CURVE AHEAD. SLOW DOWN!” Alas, that sign will bring neither the driver nor the passenger back to life.