Little urgency; less impact
It is a paradox that most organizations understand incident impact fairly well, but find it difficult to measure, whereas their understanding of urgency leaves something to be desired, but it is not so difficult to measure at all. Some of the confusion is due to the so-called “best practice” of calculating incident priority based on both impact and urgency, a practice that needlessly complicates an intuitive way of deciding in what order to handle incidents.
Why is impact hard to measure?
If a service is a means of delivering value to a customer, a service incident is an event that diminishes or destroys some of that value. Impact is merely a measure of that loss of value. There are two reasons why impact is often hard for IT to measure:
- It does not know the value of the services it delivers;
- It is difficult to assess the scope of an incident when it is first reported.
Given these difficulties, IT tends to use rough approximations ofimpact, based on such factors as the presumed number of users impacted by an incident; the so-called “criticality” of the service or of the service assets impacted by the incident; as well as the experience of IT with the customer.
Why is urgency hard to understand?
In spite of attempts in frameworks such as ITIL to define “urgency”, most IT support personnel have difficult grasping what it is and how it is different from impact. When a user calls the service desk to report an incident and the service desk agent asks the user, “Is it urgent?” (using the commonplace sense of the term, rather than its technical meaning), the user most often replied that it is indeed urgent, because he or she is blocked from doing work. But this response concerns only impact, not urgency.
The second reason that urgency is often hard to comprehend is because there are really two different impact metrics. Urgency helps to distinguish between the two of them. Unless we understand those two impact metrics, we have trouble placing the meaning of urgency.
The Two Impacts
I would distinguish between “instantaneous” impact and “cumulative” impact. An example will help to understand the difference. Suppose an incident causes an on-line order system to fail. Users cannot place orders. The instantaneous impact of that incident may be thought of as the lost value of a single order that was not placed. It is the impact right now. Suppose the service handles an average of 10 orders per minute during normal business hours. As the incident progresses, the total number of orders that are not placed accumulates. This scenario is illustrated if Fig. 1.
Fig. 1: Cumulative Impact vs. Time If our assumption that the average number of orders per minute stays constant, we see that the slope of the line stays constant.
Now, let us consider a second scenario where the instantaneous impact of the incident is the same as for the order system, but there are only five transactions per minute, instead of ten. The two incidents are shown in Fig. 2.
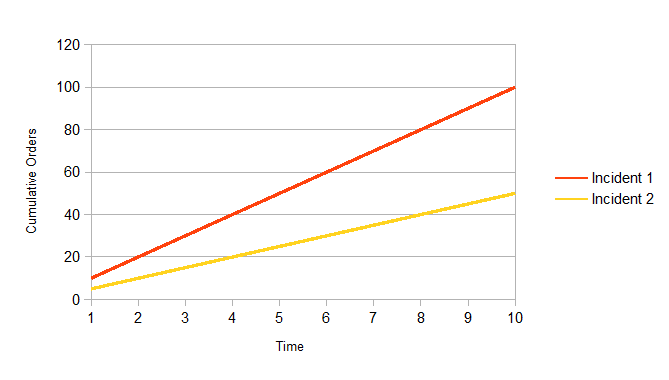
We note that the line representing incident 2 will never intersect the line representing incident 1, no matter how long the incidents might last before being resolved. The conclusion that we draw is that the relative priorities of these two incident are independent of time. Only the instantaneous impact influences the priority.
The Urgency Factor
Next, let us examine the situation where our assumption about the average number of transactions per minute is not correct. Suppose the order system is used by a concert ticket ordering service. Tickets for a major music festival will go on sale at 14:00. However, at 11:00 an incident causes the failure of the service. Given the high popularity of the music festival, if the incident is not resolved before 14:00, there will be a very significant increase in the impact of the incident at that time. Assume that this is incident 2 in Fig. 3.
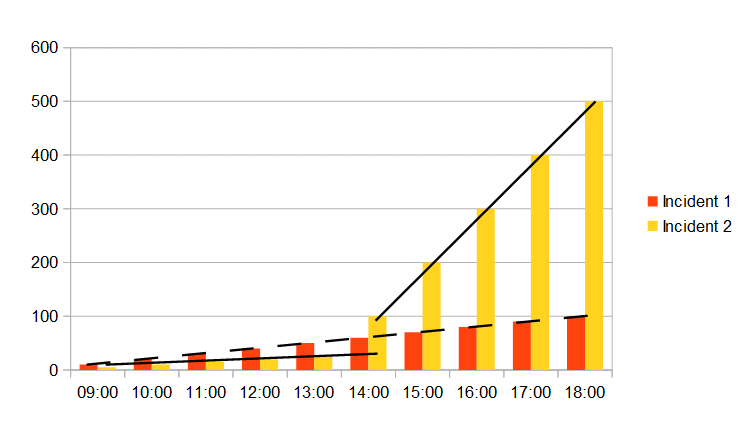
In Fig. 3, we see that incident 1 still has a constant increase in cumulative impact, as shown by the dashed line. Incident 2, however, whose cumulative impact is represented by the solid line, shows a discontinuity at 14:00. At that time, the impact has changed enormously. The incident starts to have a greater cumulative impact at that time, whereas in scenario 2, it never caught up with incident 1.
It is clear that we have a good reason to try to resolve incident 2 before 14:00, whereas incident 1, which should in any case be resolved as rapidly as possibly, has no such time at which the instantaneous impact changes significantly. Voilà! We now have a clear description of the importance of urgency in determining the priority of an incident.
Measuring Urgency
It should now be clear that the unit of measurement for the urgency metric must be time. We want to know how long it will be from now until the significant change in instantaneous impact.
From this definition of urgency, we see that urgency changes as time elapses. This makes perfect sense. Something that will happen next week is less urgent than something that will happen in the next 5 minutes.
What happens to urgency after we have passed the event horizon? In the third scenario above, what happens at 14:00 if the incident is still not resolved? First of all, the instantaneous impact increases. But more interestingly, the urgency decreases. Unless there is yet another event in the future that will result in a significant change to impact, we return to a situation where the slope of the increase in cumulative impact becomes constant, with no acceleration and no discontinuities. In other words, the urgency becomes “normal”—no greater nor lesser than any other incident without a particular urgency. Once again, only the impact should influence the incident priority, as in scenario 2.
Do incident resolvers need to know the urgency?
From the above analysis, it should be clear that urgency should be indicated as an amount of time. In principle, either an incident has no particular urgency, or the urgency could be, for example, 45 minutes or 2 hours or 25 hours. Does the person attempting to resolve an incident need to know its urgency? In theory, once you start working on an incident, you should resolve it as rapidly as possible. Knowing the urgency should not really change your ability to resolve the incident. However, sometimes an incident might be resolved in different ways, each requiring a different amount of time to implement. Knowing the time at which the impact will change might influence the strategy used to resolve the incident.
Notice a subtlety. I said “knowing the time at which the impact will change”, not “knowing the urgency.” What is the difference? The difference is that the time on the clock at which impact will change stays fixed (more or less), whereas urgency constantly evolves, as the hour becomes closer and closer to the event horizon. The resolver might benefit from the message, “this needs to be fixed by 14:00.” But we cannot expect resolvers to keep track of the changing urgency.
Urgency Buckets
Since we calculate incident priority—that is to say, the order in which incidents should be handled—based on a combination of impact and urgency, we need an algorithm to calculate that priority. In theory, if we could estimate the impact in terms of value, we could combine this with the amount of time until a change in impact, to calculate a priority. However, as we saw above, impact is not easily determined in terms of value, so we often end up with a schematic impact, such as “high”, “medium” or “low.” In this circumstance, there is no point is knowing the exact number of minutes or hours until a change in impact. It suffices to create a series of urgency buckets. The tradition is to use terms such as “critical”, “urgent”, etc., to designate these buckets.
In fact, these buckets should cover only a very restricted period of time. They should not cover the very near future. For example, if a user informs the service desk of an incident and we learn that the impact will change radically in one minute, there is probably nothing that can be done during that very short lapse of time, especially if the incident needs to be escalated. When recording the incident, assume, instead, the new level of impact, with no particular urgency.
Similarly, it makes no sense to describe urgency too far in the future. Let use suppose that 95% of all incidents are typically resolved the same business day and, in any case, in no more than 8 hours. It makes no sense to describe an urgency that goes beyond those 8 hours, because the incident is most likely to be resolved in any case before the event horizon of a change in impact. As a result, urgencies should be grouped in 2 or 3 buckets at most, in addition to normal urgency. One bucket might be 30 to 90 minutes; a second bucket 91 to 200 minutes; a third covers 201 to 300 minutes; anything over 300 minutes is considered to be normal urgency. Of course, the exact size of those buckets depends largely on the capabilities of the organization to resolve incidents rapidly. If those capabilities are very low, it might be necessary to expand the buckets, just as a superbly performing organization might find value in contracting them.
Urgency and service management tools
I will close this discussion with a word about service management tools. The vast majority of tools in the marketplace ignore this interpretation or urgency. For these tools, urgency is simply a value plugged in to a matrix to calculate priority. There is no real meaning or logic built in to the category.
In fact, tools ought to record the time of the event horizon, the time at which impact is expected to change. On the basis of this time and the current time, the urgency should be calculated, not manually input. Furthermore, the tool should automate the changes to urgency as time advances. A more sophisticated tool should also manage a business calendar that allows it to distinguish between business hours and non-business hours, so as to calculate correctly any changes in urgency.
The fact that most tools do not implement this understanding or urgency is probably at the heart of much of the misunderstanding among service management practitioners about what urgency is and how it differs from impact and from priority.
 The diagrams in this posting are licensed to you under the terms of the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.
The diagrams in this posting are licensed to you under the terms of the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.
[…] The essential difference between a lean approach and this process is one of push vs. pull. In a lean approach, the assessment of the priority is done at the moment of pulling a work item from the ready column on a kanban board.3 Priority should be determined on the basis of the risks of finishing the work when needed. The typical impact vs. urgency matrix recommended by common frameworks and implemented in most service management tools is not well adapted to this concept. That being said, the dominant problem concerns how organizations interpret urgency, an issue I have discussed at length elsewhere. […]