A vicious cycle in incident management

Lean incident management is the resolution of incidents in a manner respecting lean principles. Being lean allows us to significantly reduce the extent of the control activities in the process and the number of organizational roles created to exercise those control activities. For, I have often seen a vicious cycle in organizations having a command and control culture: quality assurance and managerial tasks are increased due to the existence of a headcount to perform those tasks, and the headcount is increased due to the imagined need to perform those QA and managerial tasks. This vicious cycle encourages the addition of ever more layers of control—be they procedural, organizational or technical—as the process becomes increasingly complicated. Shall we attempt to play the role of Alexander and cut through this Gordian knot in one fell swoop?
This article is addressed particularly to those who are interested in a lean approach to service management but cannot imagine how their current ways of managing incidents, among other service management objects, can be revised to benefit from lean management. The proposals made here should be taken as examples of what might be done to resolve incidents in a lean way, rather than normative rules of what should be done.
Incident resolution process scope
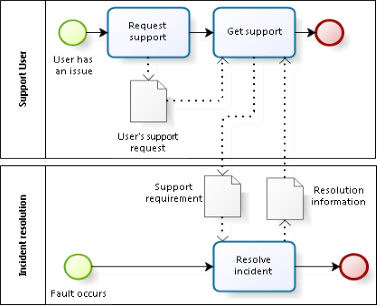
Before articulating a lean value stream for resolving incidents, let’s be clear about the scope of the process. I consider the process of resolving incidents to be distinct from, albeit closely related to, the process of supporting service consumers. For those who prefer the complexity of so-called “end to end processes”, I ask you to bear with me as I explain the approach.

The typical issues behind my assumption about process scope are commonly known. If 100 users of a service experience the impact of a service incident, then 100 different instances of a support process may be performed. Can you imagine how a user would feel if, when calling a help desk for support, were told “We won’t help you because someone else already reported the same incident!”1 As for incidents, however, whether that incident is reported by one user, one hundred users, or no user at all, what we need to do to resolve it requires only one cycle of the incident resolution process. In short, a cycle of incident resolution has a one-to-many relationship to the cycles for user support. A fault in the delivery of a service is not the same event as the request by a user for support.
A lean incident management value stream
Elsewhere, I have examined the possibility of having a single value stream applicable to all service management processes. Having a single value stream would vastly simplify the kanban board for a team performing a wide array of service management processes. In this article, I am looking specifically at incident resolution as an example of how a lean management approach may impact process definitions and organizational structure.
Handling incidents is a classic example of work suited to adaptive case management. There are several key patterns of activities that are commonly used to resolve incidents. However, we only know for sure after the incident is resolved that any given activity in the process has delivered the right output.2 Furthermore, the resolution of each different type of incident can be, in reality, a distinct process. A few examples illustrate these points.
At one extreme is the incident that can be resolved as soon as it is detected. More often than not, such incidents have been seen many times before and the incident resolver knows precisely what to do. For such an incident, a very simple value stream of only one activity is perfectly adequate.
An organization may well have defined incident models or templates to handle such simple incidents. Typical examples would be incidents due to known errors where the precise method for resolving the incident is documented and well known. Resolving this type of incident includes three patterns of activities:
- Characterize or profile what has gone wrong
- Retrieve the solution appropriate to that profile of incident
- Implement that solution.
At the other extreme are incidents requiring multiple iterations of attempts to characterize, diagnose and resolve them. Such incidents tend to be rare and are likely not to have been seen before. An example might be the case where an application appears to users to be frozen but there is no evidence in any logs or from any monitoring devices that any of the service system components are at fault. When the infrastructure is multi-layered and complex, it might be necessary to try to replicate the incident in order to get a grip on what to do to resolve it. When the incident is due to an application bug that manifests itself only as a result of rare data paths through the system, traditional resolution strategies, such as rebooting, might prove to be ineffective.
The way in which we resolve an incident that we have seen hundreds of times before is almost certainly different from the way we resolve an incident we have never seen before. Resolving the latter type of incident includes three patterns of activities:
- Characterize or profile what has gone wrong
- Identify an action for righting or mitigating the wrong
- Implement that action

As I asserted above, we can not be sure that activities 1 and 2 have been done correctly so long as activity 3 is not confirmed as having succeeded. Are we to therefore define a value stream where the work item shuttles back and forth (see Fig. 3), as many times as necessary until the incident is truly resolved? This hardly makes sense, as it needlessly over-complicates the modeling of the work and prevents you from easily identifying on a kanban board which items are blocked.
Thus, instead of defining a value stream with three activities, susceptible to multiple iterations, we may show the value stream as including the single activity of resolving the incident, including whatever profiling, investigation, planning, testing and resolution attempts as are necessary to achieve the goal of the process. A simple SIPOC diagram of this incident resolution may be found in Fig. 4.

The process is triggered by the receipt of information that something has gone wrong. This information could come from a user requesting support, from a system operator identifying some anomaly or from some automated monitoring system. Let us examine in more details the principles realized in a lean incident management process.
Profiling the customer’s issue
Once triggered, the process must characterize what has gone wrong. From the customer’s point of view, this characterization or profiling is valuable, because it demonstrates that the service provider understands the issue. The customer should therefore get some positive feedback demonstrating that the provider and customer have an aligned understanding of the issue. Note that this initial alignment only concerns the articulation of the issue, not an analysis of the causes or of the proposed solution. This alignment helps prevent a situation where the service provider does work that does not really resolve the customer’s issue.
Identifying how to resolve the customer’s issue
As we stated above, in many cases the profiling of the issue leads directly to the resolution action. In the Cynefin framework, this would be an “obvious” incident. Of course, it might happen that the resolution action fails to resolve, in which case the profiling might have to be redone. What appears to be obvious at first blush might turn out to be “complicated” or “complex”.
But in many other cases, where the type of incident is not well known, it is necessary to decide what to do about it to achieve a resolution satisfactory to the customer. If the profiling of the incident is essentially a matter of correctly classifying it in a taxonomy of known types, the incident might be considered as “complicated” in the Cynefin framework. If, however, if the classification is much in doubt, then considerable probing might be required, indicating that the incident is “complex” from a Cynefin point of view.
This identifying activity adds value, from the customer’s perspective, in two ways. First, and most obviously, it allows the service provider to determine how to resolve the incident. Second, that resolution sometimes involves the participation of the customer. The customer must be capable of performing what is requested and must be available to do it. Let me give some exaggerated examples to illustrate these points.
Suppose there is a bug in an application. One might theoretically guide the customer through the process of correcting the source code, compiling it into an executable, testing it and updating the production version of the executable. With rare exceptions (for example, the case of a software editor supporting a software development team), planning a resolution requiring this level of customer participation is probably unacceptable to the customer. Similarly, a resolution that requires a long presence by the customer outside of business hours might not be acceptable in many cases. A third example would be a planned resolution that requires a level of access to the customer’s resources that might be unacceptable to the customer.
The issues described in previous paragraph are handled in different ways, according to the paradigm of the provider-customer relationship in use by the service provider. When a service provider treats its customers like simple recipients of service outputs, these issues are generally resolved by establishing general terms and conditions for support. While the provider may view such terms and conditions as means for clarifying the services provided, they also act as constraints that may not be suitable to the customers’ needs. When a service provider views the customer as a partner in the co-creation of value, it may be more flexible and open to ad hoc handling of complex situations.
Once the service provider has determined what is needed to resolve the incident and, if needed, the customer agrees with the planned resolution, the resolver may attempt the resolution. Again, if that resolution fails it might be necessary to revisit the plan, or even to revisit the initial profiling of the incident.
Resolving the customer’s issue
Whether the service provider needs to investigate how to resolve the incident or not, the final step is the resolution itself. This is the moment of truth. Either the incident is indeed resolved or there is a defect in the process. The defect might be one of:
- Incorrectly applying the identified resolution
- Incorrectly identified resolution
- Incorrectly profiled incident
If there is a defect, the process is recursively applied. In other words, identifying the defect is analogous to the original profiling of the incident. Deciding whether to repeat the resolution (correctly) or go back even further is analogous to identifying the solution. And redoing the profiling and/or the solution identification and/or the solution is analogous to solving the incident itself. If the process is hopelessly out of control, it might even be necessary to iterate again the corrective actions. Depending on the nature of the defect and the manner in which it is handled, such incidents might range from “complicated” to “complex” to “chaotic” in the Cynefin framework.
To conclude this section, we note that a single activity value stream, consisting only of “resolve the incident”, will cover all types of incidents. In case the incident is complex or previously unknown by the resolvers, it might be useful to break down that activity into steps. The various and ambiguous paths leading to incident resolution may be profitably analyzed in more detail with reference to the Cynefin framework, as we have seen. But that is a subject for a separate article.
What is not lean in so-called “best practice”?
In Fig. 4 we see an incident management “process” as based on a common framework.

Let’s leave aside observations such as the fact that the diagram cannot represent the real flow of work in most cases. Let’s analyze, instead, the activities in this process against lean criteria.
Identify
We have started a process to manage incidents. And lo! The very first step is to determine if we have made a mistake, if the event being managed is not really an incident. If such process defects occur in a lean context, the approach is to understand why such mistakes are being made and take actions to eliminate them. We should not enshrine in the process the management of mistakes.
Log, Categorize, Prioritize
The essential difference between a lean approach and this process is one of push vs. pull. In a lean approach, the assessment of the priority is done at the moment of pulling a work item from the ready column on a kanban board.3 Priority should be determined on the basis of the risks of finishing the work when needed. The typical impact vs. urgency matrix recommended by common frameworks and implemented in most service management tools is not well adapted to this concept. That being said, the dominant problem concerns how organizations interpret urgency, an issue I have discussed at length elsewhere.
In a lean context, where work is organized and tracked using a kanban board, priority is determined at the moment of pulling a kanban card from the ready column, before the work on the process has really started. In the process diagrammed in Fig. 4, the priority is determined after the process has started. In the end, however, this is a minor difference.
Major incidents
A lean approach makes no necessary distinction between the value stream for resolving major incidents and other types of incidents. Whatever the particulars of the major incident procedure, from a lean perspective, there is only one value adding activity in incident management—resolving the incident and restoring the service. Since this activity is already part of the process, any other activities for a major incident are non-value adding, or are parts of processes other than incident resolution.
Some may object that major incidents require special communications with specific stakeholders and these communications add value. This is certainly true in many cases. But, from a value stream perspective, the only difference between a major incident and any other incident is the identity of the stakeholder receiving communications, not the fact of communicating.
Diagnose initially & Investigation and Diagnosis
The distinction between these two activities is based on the premise that there are various lines of support in a service provider organization. I will return to the question of whether such lines of support are lean or even a good idea at the end of this article. Be that as it may, based on the results of the initial diagnosis, there may or may not be some more or less complicated reassignment of work on the incident. The transfer of information from one line of support to another, the waiting time during reassignment and the all too frequent rework of the initial diagnosis are all forms of waste. A lean value stream will not accept that these are normal ways of working. It will have sought to eliminate these forms of waste. Thus, a lean process does not include a decision asking whether the diagnosis was done correctly and, if not, the work needs to be reassigned and redone. Furthermore, as we mentioned above, we cannot know whether the diagnosis is truly correct until the resolution itself has succeeded. As a result, the only truly valid reason for reassignment of work after diagnosis is if the initial assignment was done incorrectly—yet another form of waste that we should seek to eliminate, rather than preserve in the process.4
Resolve and Restore
The resolve and restore activity is perfectly lean, as it is the one activity in the process that is unambiguously value adding. Whether the activity is performed with any types of waste built in is, however, a separate question.
Close
The closure activity is really a hotch-potch of tasks that need to be analyzed individually. Closure categorization is not really a value adding activity, from the customer’s perspective. However, I can readily see the advantage of doing it. I would put this task under the Resolution activity. Who could better categorize what was done than the person doing it?
Surveying user satisfaction is not part of incident resolution at all. The process by which you get such feedback is not specific to incidents and should be generalized to all processes. The task should be removed from the process. I follow here a principle elaborated in my article Three Process Architecture Principles, wherein a single activity should be performed in only one process, rather than duplicated in many different processes.
Documenting the incident assumes that the incident was inadequately documented by the people doing the documentable work. Rather than adding a task to do work that ought to have been done before, or even to control the quality of that work, a lean approach seeks to understand the causes of that inadequate work and to remove or mitigate them. The waste of rework is thereby reduced.
Identifying whether a problem record should be opened is more reasonably done as a result of having searched for an existing problem record for the type of incident and not having found one. Clicking on a button to do so takes an insignificant amount of time and therefore does not really delay incident resolution. In comparison, having to redo the work of searching for a problem record or known error, in order to decide if a new one should be created, is a form of waste that takes significantly longer.
Controlling the quality of the recorded information is a classic form of waste that the lean approach attempts to eliminate. The need to perform this activity implies that other activities upstream were not performed correctly, that there are defects in the incident record. But a core lean principle is to avoid passing any defects down the process. One might argue that documenting an incident correctly takes time that is better spent in resolving the incident. Unfortunately, this reasoning fails to take into account the impact of higher costs or of the lower availability of personnel, who spend time fixing up the mess others make, rather than resolving incidents themselves (or performing other value-adding activities).
In conclusion, most of the tasks performed with the closure activity are either forms of waste or should be part of a different process. Therefore, the closure activity should not be performed in a lean process. There would be no significant difference between a status of “resolved” and a status of “closed”.
What does a lean incident management process mean for organizational structure?
As the organizational structure of incident resolvers becomes increasingly complex, there is an increasing need for the reassignment of tasks. When the principal of technical specialization is embodied in organizations, such reassignment becomes a necessary evil. Each reassignment involves a certain amount of waste, mostly from waiting but also from the defect of mis-assignment and the resulting rework.
How important is the waiting time associated with the assignment of incidents? An analysis of the incident of some 65’000 incidents occurring over 16 months in a certain organization shows the average waiting time to be 64% of the total resolution time (viewed in terms of absolute calendar time). If we look only at working hours and exclude holds due to users, that figure is 35%. In other words, somewhere between ⅓ and ⅔ of incident resolution time was the waste of waiting time in that organization. I invite readers with access to the relevant data to calculate these values and submit them here.
The question is what can be done to simplify the handling of incident assignment and reduce the associated waiting time? I suggest two ways of making incident resolution leaner and simplifying the organizational structure needed to resolve incidents. The first strategy is to eliminate tasks that are supposed to check and improve the quality of incident records. The second is to structure incident support teams around the services being provided, rather than the technologies used to support those services.
We have seen above that tasks associated with checking and updating incident records for work done by others is a non-value adding activity. Insofar as these tasks are performed by persons other than those who ought to have updated the incident record correctly in the first place, they imply a re-assignment of work, inevitable waiting time and forcing people to perform non-value adding work, rather than some other value adding work.
For those who might argue that the quality of data in incident records is important to ultimately providing value to customers, I would fully agree. However, as with any lean problem solving, the approach should be to root out the causes of poor data entry in the first place, rather than to institutionalize that poor data entry and the checking and correction of that data.
The second suggestion, to organization support teams along the lines of services rather than technology, is a much more radical change. There is hardly any medium to large size service provider that does not use technology as the basis of specialization, so such changes are difficult for them to countenance. It is easier to imagine implementing a service-based structure in a greenfield situation. For existing organizations, the transition might pass via the introduction of new services or new service lines, each of which would have its dedicated design and support team.
The argument in favor of specialization on the basis of services rather than on the basis of enabling technologies needs be more comprehensive than relying solely on the advantages in lean incident management. I have already started to address this theme when I asked if service desks were really necessary. I will continue to examine other facets of the question in future articles.
![]()
 The article Lean Incident Management by Robert S. Falkowitz, including all its contents, is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
The article Lean Incident Management by Robert S. Falkowitz, including all its contents, is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
1I am aware that many organizations view the support of individual users to be a burden, sometimes impossibly heavy. They limit support to the briefest of messages that they are aware of the situation (with the strong implication of “…so please don’t annoy us more than necessary…”). And yet, such behavior fails to capitalize on these moments of truth. They neither help to cement the customer-provider relationship, nor do they make any attempt to mobilize the users’ assets to add value to the incident resolution or to the specific support needs of each user. But this issue is off the topic. I plan to address it in a future article.
2It is perfectly possible to resolve an incident after having mis-diagnosed it. Re-booting a computer, for example, hides many an egregious error. But we should distinguish between sufficient diagnosis for resolving the incident and sufficient diagnosis for identifying the causes of the incident. The latter is generally neither expected nor necessary in an incident resolution process.
3If you are not familiar with these concepts, you may wish to consult a general introduction to kanban or view various articles or presentations I have made on the subject, such as: Priority, Cost of Delay and Kanban, Increase service value with kanban, Cross-functionality, Kanban and service design, Daily Improvement with Kanban or Kanban as an ITSM Best Practice.
4I recently analyzed the incidents in a medium large organization and found that on average about ⅔ of the resolution time was spent in waiting for reassignment from one line of support to another. It seems to me that any organization interested in significantly reducing the resolution time of incidents should seriously investigate the factor that contributes the majority of time to the overall process!
Very good article, although I do not agree with “resolving the incident and restoring the service” as there is a balance when you have a major disruption to the business where you need to restore, even to compromise the ability to resolve the incident.
Resolve versus closed is about confirmation so teams do not end up struggling with seeing the wood because of the trees, invariably adding cost and delays through doing the same activity multiple times. The value is not repeating the same activity.
I do agree there is not a difference between incident classifications although politically organisations feel there is value in specific communication when major incidents occur, even though they do not test the reaction from those communicated and in some cases the business are not on the communication. Further exacerbated by a propensity to talk technical as opposed to the business impact.
Value would be derived if organisations knew the audience and what the message should be, aimed at business users not IT people as is predominately the case. Enabling the business to respond to failures in technology quickly is where the value lies, with a joint effort to restore or resolve depending upon impact.
Very good article highlighting opportunities for organisations to move forward and adopt an approach that not only takes out needless wastage but allows people to contribute and grow. Look forward to the next article.
Thank you for your feedback, William. I am not sure I understand your first two paragraphs. We seem to differ on what “resolve” means, but I cannot determine how you understand it. As for the difference between resolving and closing, perhaps adding some detail would clarify what sort of scenario you envision.
Robert, maybe what William does not agree is the word AND in “resolving the incident and restoring the service”. For example it should be AND/OR in his view if I get the paragraph right.
But it is not the main point of your analysis, isn’t it?
The best way to lean up incidents is to avoid them completely. Start with service design, continue through delivery and improvement efforts.
I agree with you wholeheartedly, Matt, that an ounce of prevention is worth a pound of cure. But given that even the best service systems do not reach such levels of perfection and that some parts of our service systems, notably our customers, but also our suppliers, are not entirely under our control, we still need to think about how to resolve those pesky incidents. So there is still a place for doing that work better and faster.