In this second article in my series on artificial intelligence and service management, I will provide a concrete example, namely, using AI to help manage service requests and other support requests from service consumers. I will apply the framework described in the first article in this series, A Model of Artificial Intelligence in a Service System. The example I provide in this current article will provide illustrations for many of the future articles in this series.
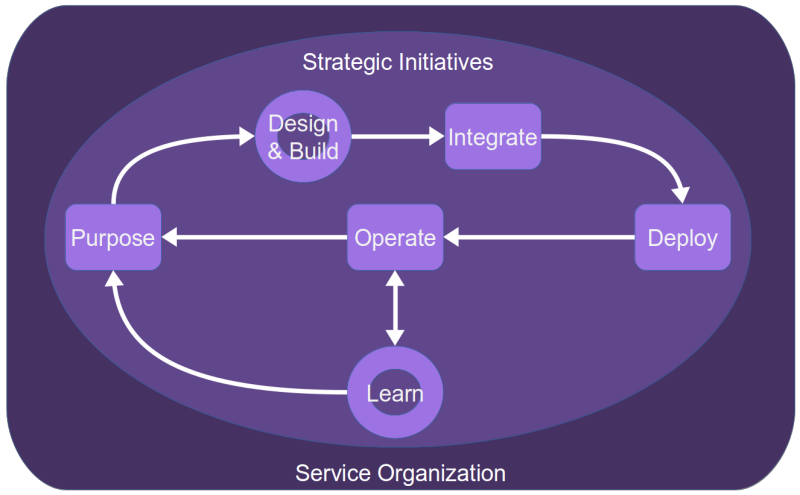
AI Applied to Service Management
- Identifying opportunities for services within market spaces
- Optimizing the structure of complex service systems
- Optimizing the operations of service systems, such as minimizing energy consumption in a data center
- Automated testing of service systems
- Automated changing of components of service systems
- Automated classification of service requests
- Identifying operational risks
- Identifying faults
- Identifying potential causality
- Segmenting customers
- Analyzing emotions of service stakeholders, especially consumers and users requesting support
- Tuning of services to improve customer satisfaction
- designing new and competitive services
An Example from Service Request Management
I have chosen the classification of the various sorts of requests and other communications made by service consumers to a service providers to exemplify the life of an AI in a service system. In this article, I will talk of service requests and service support interchangeably. I have chosen this example because it is within the experience of most service managers. Furthermore, artificial intelligence has already been implemented in certain tools to help achieve this purpose.
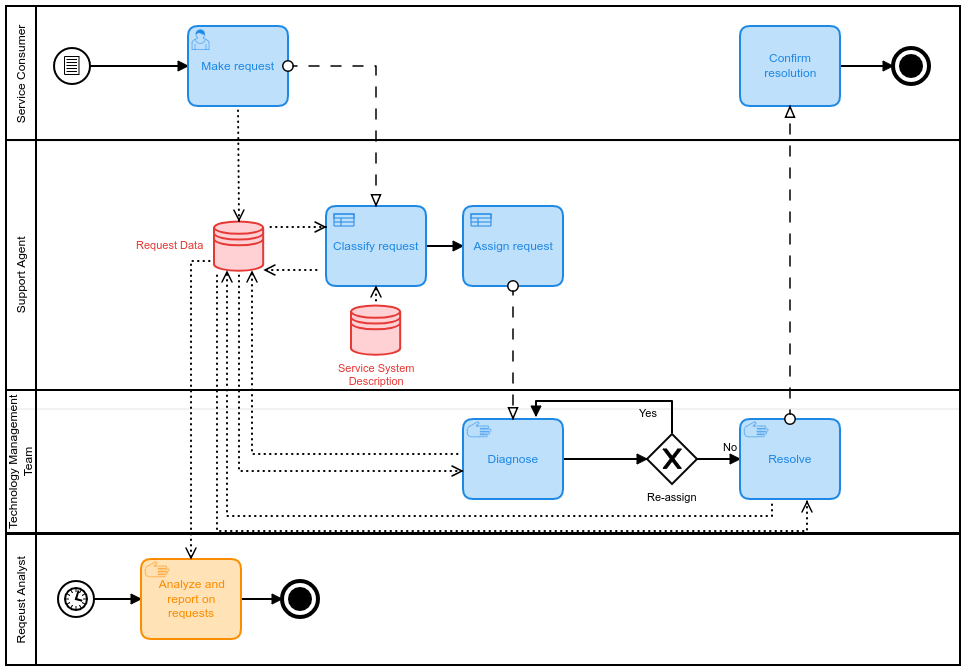
The particular purpose of the AI will be discussed in more detail below. I am assuming that an AI is used because the service provider had been having significant difficulties in resolving various types of support of its service consumer. Often, one of the factors leading to long lead times in resolving support requests is a high error rate in classification of the types of support being requested.
Let us examine how AI might be used to improve how a service provider might manage service requests.
The Cultural and Strategic Context of the Organization
In assessing the impact of the service provider’s culture on the use of AI for service request management, I will consider organizational maturity, especially as it concerns its capability to reorganize itself and the levels of risk associated with the problem of misclassification of service requests.
Organizational Maturity
A relatively immature organization might address the problem of service request misclassification by layering technology on top of its existing system, rather than seeking to resolve the problem at the level of its underlying causes. This is a classic result of a command and control culture. A management problem is detected; controls are added to address that problem.
For example, misclassification is a problem if it leads to assignment of tasks to the wrong teams. But this is a problem especially if the teams are organized according to the technology they manage, rather than according to the end to end services they provide. However, even if the erroneous assignment and the inefficient hand-off problem with technology silos were recognized, you might consider it extremely difficult to change that organizational principle. Many organizations are simply not ready for or lack the agility needed to make this sort of major change.
The maturity of the service provider organization impacts its understanding of how to manage the AI through its life. For example, if an organization naïvely believes that an AI can classify service requests out of the box, with no training, it will quickly be disabused of this notion. Understanding why a first line of support has difficulty in classifying support requests requires deep knowledge of the provider’s service system. This knowledge cannot be provided out of the box by a third party. At best, a tool can provide an algorithm for classification, but this algorithm needs to be trained by the service provider.
Risk
What is the risk to service consumers of a mis-classified request? In a rigidly structured, or tightly coupled system, the risk is that the wrong service will be provided or that the provider will attempt to resolve the wrong thing. The consumer will be greatly dissatisfied and the provider will have wasted considerable effort and resources. In a more buffered system, misclassification is likely to be detected before the service is provided to the consumer. Thus, the risk is principally in extending the lead time for delivering the correct service. This risk exists for the first case, too, where it would be greatly aggravated.
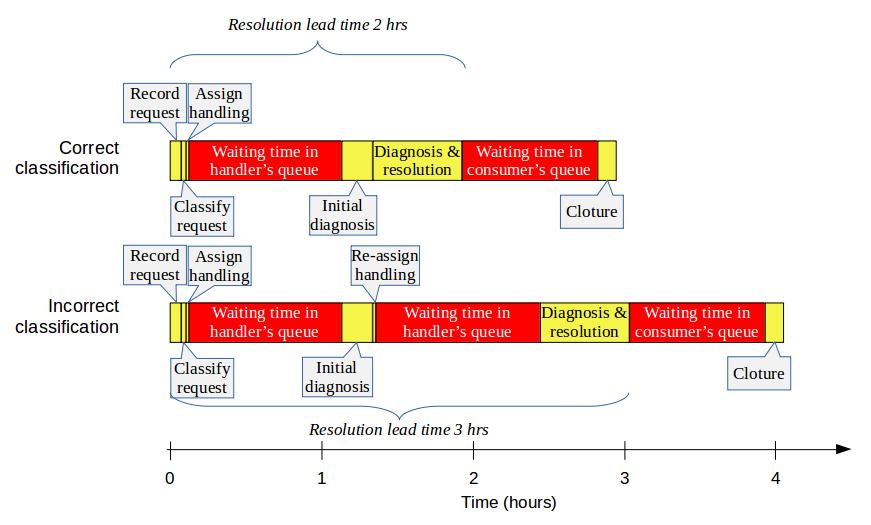
Strategies Impacting Service Requests
The service provider will also need to establish policies, be they de jure or de facto, regarding the supplier of the AI technology and the technology itself. For the case of service request classification, this issue is essentially the old “best in class” versus “integrated solution” discussion. A stand-alone classification tool could be integrated with the other tools used to support service request management. The question is whether the potential benefits of a stand-alone solution (namely, improved classification) would outweigh the costs of developing and maintaining the integration. This decision is further influenced by the capabilities of the service provider to perform that integration.
In the section below on Training I will address a particular issue that may impact the strategies for sourcing natural language processing. If you use multiple NLP back-end services, you will need to train each of them separately. You might find this necessary if you use an integrated service management tool with some NLP functionality, but you also want to use NLP for other purposes not covered by that tool.
Data Strategies and Service Requests
In a future article I will discuss the general issues of data strategies as they related to service delivery and service management. Here, I will limit myself to remarks that directly concern service requests and service consumer support.
Pre-AI data strategies for service requests are generally based on two use cases. First, it is assumed that many support requests are highly standard in nature. For these requests, models are defined to collect structured data and to limit the amount of data collected to what is deemed essential for quick and efficient resolution.
For example, to resolve a request to restore a backup of a file, the model would tell the provider to collect the following data:
- What file?
- When was the backup made that should be restored?
- Who is authorized to request a restore?
- Who has made the request
- When the restore should be made (if not as soon as possible)?
Any other data associated with the request is deemed to be superfluous, pleonastic or supererogatory, hence dilatory and inefficient.
At the other extreme are the cases of unexpected and hitherto unheard of requests. Assuming such requests are within the scope of the support provided by the service provider—which is not always the case—emphasis is placed on collecting unstructured, descriptive or narrative data. Some organizations will attempt to provide a partial structure for such data, such as describing a request in “user story” format:
The requester, who is making the request in her or his role as a [the role being played],
is requesting [some change, action or correction]
in order to achieve result or benefit [why the request has been made].
In both of these cases, there is an attempt to reduce the amount of data collected, assuming that structured, or semi-structured, data is somehow better than unstructured data. Whatever the pros and cons of structuring might be, this strategy of simplification and structuring also results in a loss of data. Assumptions are made about what is important. There is a tendency to disregard and not record other data. For example, information about the emotional state of the requester is often not recorded. The support agent responds to emotions either in trying to sedate them; empathize with them; ignore them (because they assume that only the “rational” component is worthy of attention); or they might find it expedient to raise the priority of a request just to resolve more quickly and dispense with the unpleasantness of the case.
When using AI to support work, err on the side of collecting more data rather than less data.I am not arguing that structured data should not be collected. Nor am I arguing that unstructured data should not be structured, to the extent possible. However, I am arguing that these models and structures should not automatically exclude certain types of data associated with support requests. Indeed, I would argue that a strategy should be implemented to attempt to collect more, rather than less, data, making it available to AIs that would support the analysis and fulfillment of requests.
For example, when a request is registered by telephone, the entire conversation might be recorded and made part of the request record. Such recordings are useful for more than training purposes or for evaluations of support agents. They can help reduce the impact of the biases of support agents regarding what is important. They can help make objective the analysis of requester intent and emotional state. Such information might be useful, for example, in the assigning work to agents. Certain agents might be more skilled than others at handling certain emotional states.
Defining the Purpose of the AI
First of all, the scope of the AI must be clearly stated and constrained. Suppose you wish to improve how requests from service consumers are handled. In the current state of the art, you cannot design an AI whose purpose is to “manage service consumer requests.” You can, however, decompose that management into detailed tasks. Some of those tasks might be good candidates for automation using AI.
It is often the case that tasks are not correctly assigned to teams. This can result in huge amounts of waste and dissatisfied consumers and providers. Thus, one example of such a task is the classification of service requests. What is the problem that organizations hope to solve? Often, the service provider is organized into teams of specialists, based on the principle of technology. Thus, there are network experts, server experts, client experts, database experts, application experts, etc. I set aside the fact that such an organization might be extremely inefficient for handling the flow of work.
Before described to steps to build and deploy an AI for service request classification, I will briefly review some of the other strategies that have been used to solve the problem of poor classification.
Other Strategies for Classification
In deciding whether an AI best meets a defined purpose, it is useful to review other possible solutions. Several strategies have been tried to address the problem of classification:
- Offloading classification to the service consumer
- Improving the classification skills of the first line of support
- Implementing tools to enhance communication between teams
- Using simplistic classification schemes, often based on components involved
These common strategies have all various difficulties:
Offloading Classification
Offloading classification to service consumer, otherwise known as self-service, often requires complex taxonomies of request and support types. The user interface often navigates the taxonomy via a series of hierarchical drop-down lists. The complexity of this interface and taxonomy befuddles the non-specialist consumer, who has little motivation and no time to learn the details. Thus, captured classification is often too general to be useful and often wrong. The poor quality slows down handling because it requires a secondary control and qualification to correct errors and provide needed detail.
Improving Classification Skills
Improving the classification skills of the first line of support sounds like a good approach. It embeds knowledge within the organization and helps avoid the waste of misdirected tasks. Unfortunately, this strategy is often sacrificed on the altar of saving costs. First line of support personnel are often outsourced, resulting in higher turnover rates and a failure to embed knowledge within the service provider organization. They are treated as low-level jobs that do not merit good salaries, thereby adding to turnover rates and discouraging people with the interest and the skills needed to do a good job of classification. In addition, the transfer of the knowledge required for good classification from the technical teams to the first line of support is often considered to be a “nice to have” task in any project. Consequently, it is among the first tasks skipped when a project is inevitably taking too long or costing too much.
Enhancing Communications Tools
It has become fashionable in the past few years to implement tools to facilitate inter-team communication. The benefits of such a strategy are based on the astonishing proposition that people who have communicated poorly outside of their own teams would start to communicate well, if only they had the right tools. It might be true that the novelty of implementing the latest technology will attract the attention of died-in-the-wool technologists. It might also be true that young employees, who have been using a certain communication technology since their tenderest of ages, will happily continue to use such technologies in the workplace. But adding a layer of technology to foster communication increases the degree to which work is interrupted. Interrupting work and the associated context switching in the brain are poor ways of reducing lead times for work. Instead, they increase the waste of context switching and the stress of trying (but failing) to work on multiple tasks at the same time. Thus, while communications tools might show some benefits, they also bring with them a new set of problems to solve.
Using Component-based Classification Schemes
- the actors in the initial exchange of information about the request are often not aware of more than the consumer’s device, the application being used and the edge networking connections
- issues often need to be resolved elsewhere in the technology stack
- errors or incomplete information in the configuration database may lead to misclassification
Building the AI
So the service provider has decided to improve classification, rather than attempting to remove the underlying issues that make misclassification a problem. To build an AI to help improve classification, it needs to gather relevant data, model how that data will be processed and perform the initial training of the resulting AI. These steps are highly iterative. Furthermore, they include testing, as appropriate to the culture and maturity of the service provider organization.
Gathering the Data
What data is available for the classification of service and other support requests? In general, a service provider will have:
- the record of the initial request by the service consumer, including its initial classification
- a catalogue of types of service or support requests
- a database of service system components, possibly showing their interconnections
- an organizational structure describing all the entities to which a request might be assigned
- records of the patterns of assignment and reassignment of tasks to handle the requests
- possibly some form of feedback from the actors involved about what worked well for classification and what did not
Since the purpose is explicitly one of classification, it will be necessary to use labeled data for the training that will follow.1 In other words, for each record of a service request used for modeling and training, the correct classification (and how does that classification results in assignment of the request to the correct team) must be recorded in advance of the modeling and training exercises.
Now, we would never think of developing an AI for the purpose of classification unless there were a considerable degree of misclassification. Therefore, it is important that the data sample used for modeling and training be reviewed and corrected by subject matter experts.
You might be tempted to use shortcuts to address the problem of bad data. One shortcut is to arbitrarily filter out data from sources that appear to be unreliable. This approach is likely to introduce significant biases to the modeling and training data. Another shortcut is to handle the problem of bad data in the live environment, as part of the continual tuning and improvement of the AI. While this approach might work, there is also a strong risk of the AI’s performance being too poor at the start to convince the stakeholders of its value. As a result, the whole effort might be abandoned before it starts to show much value.
Failure to do a review of data quality will result in an AI that simply repeats many of the same mistakes that existed in the past. This is particularly important because the distribution of request types is usually highly skewed. Thus, nearly 1/3 of all requests might be for password resets. The top ten requests might account for as much as 90% of all requests. But these requests are the easiest to classify and the least likely to be in error.
So, a very large number of requests occur relatively rarely. Inversely, most of the errors in classification are likely to occur among the rarer types of requests. To use an analogy, a physician is probably a pretty good diagnostician for illnesses that she or he sees every week. Diseases that might never have been seen before, or only very rarely, are much harder to diagnose accurately, even though they might tend to be more debilitating.
Typically, the data should be split between training data and testing data. Since service and support requests tend to be highly cyclic and seasonal, both sets should include many examples from all parts of all cycles and from all seasons. If this data is not available, Then it might be possible to use live data to train or to test. If there are annual cycles in the data, then training on live data might take much too long. The only alternative is to use synthetic data, generated in a random way, much as a Chaos Monkey can generate random faults in a live system.
It is probably not a good idea to use historical data that is too old. This is because there are trends in the types of requests being made, changes in organizational structure, drifting in the jargon used by the organization and changes to the services themselves. Training on data that is too old might result in irrelevant classifications.
This is a good time to define metrics for the quality of the classifications and to make baseline measurements, before the AI classification component is implemented. You should also set a target for improvement in these metrics. Some of the metrics that might be useful are:
- How long does it take to classify correctly
- What percentage of requests are classified correctly
- How much does it cost to develop, operate and maintain the AI
Modeling the AI
Modeling the AI should take into account all the structured and unstructured information available. This would include the time and date of the request, the full text of the request and any descriptive material available, the identity of the person on whose behalf the request is made, the service system components available to that person (services, devices, etc.). It might also be the case that the eligibility for services is contractually defined. In this case, it is important to have a description of that eligibility.
In all likelihood there will be a gap between the data available for modeling and the data that the modeler would like to have. Recognize, then, that the initial model is likely to evolve as more data become available in the future. This is especially true if the virtuous cycle2 of AI use encourages improvements in data strategies.
Every service provider will offer a different set of services, have a different set of service consumers and different types and amounts of data concerning the service requests. Applying a generic model developed elsewhere is likely to yield highly mitigated results, except for the obvious cases where no one really needs an AI to help support the work.
The work of developing a model is highly technical. I will not go into the details of how to do it. Fundamentally, it involves identifying the factors that strongly indicate the desired classification. A common modeling method will determine some form of regression of the data. The end result of the model will be a means of assessing each of the components available as input for the classification of the request, providing relative weightings to the different available inputs, and describing how to combine them to determine the final output, the classification.
Let’s examine a few examples of requests and what issues need to be handled by the model.
I was trying to log in the FI module of SAP but it rejected my credentials. It’s been a few months since I logged in and I seem to have forgotten my password.
So what are we looking at there? Is it a simple case of faulty user memory and forgetting a password? Does the person even have an account in that application? Is it possible that someone has pirated the account and changed the password? A natural language processing unit will parse the text and identify certain key entities, such as “SAP”, “password” and “forgotten”. The AI might also compare the identity of the caller to the authorizations, according to LDAP records or even SAP records.
I was performing the annual closure function in Whizzy when the following error message appeared…
Many tasks, and their related data, are highly seasonal. The timing of the request within the seasonal cycle might have a strong impact on its classification. In addition, many of the components of a service system are idiomatic. “Whizzy” is the organizational jargon for a certain application. Thus, the model cannot depend exclusively on a standardized list of component names.
While working on my computer, PCGV0014, everything was fine until around 11:00, when the screen froze and no longer responded to the keyboard. I had been using Calc in LibreOffice at the time.
The narrative provided by the service consumer mentions several entities, including the computer in use and the application being used. The model might take into account the possibility that some of these entities are irrelevant to the issue and that there might be a hierarchy of components. Misinterpreting the information provided might result, for example, in assigning the task to a desktop technician, whereas the real issue is a bug in an application. On the other hand, knowing the platform and being able to look up its configuration might result in sending a technician to upgrade the device.
After logging in to the account xyz, the file that was opened did not show the updates performed earlier this morning.
The model should be alert to the possibility that the request concerns a third party. Some systems include this information among the structured data of a request, but that data is not always reliable. Other systems rely wholly on the unstructured request narrative to provide this fact.
Training the AI
The model consists of a series of so-called “activation functions”, among other components, each function running in each node of the artificial neural network of the AI. These functions progressively transform the inputs (the structured and unstructured data used for training and testing) into an output (the probable classification). The training phase tunes the parameters of these functions so that the AI becomes increasingly reliable in determining the desired output. Ideally, as training progresses the output values converge on the desired results.
The weighting of the parameters reflect the artificial neural network’s probabilities of the possible intermediate and final outputs. Let’s take the example above of a computer that crashes while using a certain application. By correctly classifying the event, it will be assigned either to a technician who will work on the computer, on site, or to an application administrator who will investigate possible configuration errors or bugs in the application. A wrong classification will significantly increase the lead time to resolution.
Levels of Confidence
The purpose of training is to determine the most probable classification, given all the inputs provided. Thus, each output is associated with a confidence level, ranging from 0 (impossible) to 1 (absolutely sure). The AI will output what it esteems is the value in which it has the highest level of confidence. In practice, confidence levels above around .7 are considered to be very highly probable.
The level of confidence differs from human classification only in terms of its transparency. Unless an output is obvious and trivial or can be calculated by some unambiguous formula (in which case there is no need for an AI), human classifications also have a probability. When we say, “I am sure the classification is x”, what we really mean is that my confidence in the classification is high enough that there is no point is doubting it. When we say, “I think the classification is y”, we are saying that we are confident enough to express an opinion, but we are not sure. Often, we refuse to express any opinion at all because we are not sure of ourselves. When we factor into these classifications the various cognitive biases of the person and unstated assumptions, we see that the user of the classification should only have a certain level of confidence in the human-generated classification. The difference with the AI generated classification is that the level of confidence is explicit, whereas with human classifications, we rely on unstated assumptions to assess our confidence. We implicitly think “That guy is very reliable. I trust his judgement” or “The last time I depended on his answer, I was led astray. I better double-check this time” and so forth. And thus we add our own biases on top of the classifier’s biases.
After training, the input of this example might result in an assignment to the desktop technician with a confidence of .2, an assignment to the application administrator with a confidence of .75 and the remaining .05 distributed among other assignments. Consequently, the AI will output a classification that leads to assignment to the application administrator.
On the other hand, the way in which the training leads to this result is not very transparent. It takes into account all the inputs and the defined model so as to make its probabilistic calculations. The training is not like the rule-based analysis that humans might use, analyses subject to very many biases. That does not mean the AI is unbiased. It is subject to all the biases in the selection of the training data, in the model itself and in the biases of the subject matter experts who labeled the training data with the desired classifications.
Training a Natural Language Processing Component
Integrating the AI
Since our AI has a very circumscribed purpose—to classify service requests—it serves no purpose in isolation. It must be integrated into a broader service management system.
While you might favor a solution where the AI function is part and parcel of a general service management tool, this is not always an option. When implemented as an external tool, that tool should be interfaced with the various sources of data described above. It might also be desirable to realize the AI as an independent tool if the general service management tool lacks the desired functionality or effectiveness.
For more background information about these integration issues, refer to the discussion above about strategies.
Deploying the AI
There is a distinct possibility that there is insufficient training data for effective classification. In this case, the AI might be rolled out in phases. In one approach, the AI uses the live data as an ongoing source of training data. The automatic setting of classification is not enabled until sufficient training is obtained.
In the case where the first line of support is not centralized, there might be a roll-out team by team. The first team to use the AI would also serve as a pilot demonstration of the technology, allowing for additional adjustments to the model and the training before further deployment.
Operating the AI
The operation of the AI may take one of several forms, depending on whether the service consumer is making requests to a self-service portal or to a human support agent. In the case of a self-service portal, the most likely interface will be a chatbot, whether typed or oral. The unstructured data to input to the AI will be the entire transcript of the chatbot session. Note, though, that some chatbot tools can be configured to gather structured data, too. In the case of making requests directly to a human agent there are several possibilities for capturing the narrative of the request. One possibility is the traditional method wherein the agent types a resumé of the request into the support tool. Another possibility is that yet a different AI automatically transcribes the conversation, if it is oral. Finally, communications via chat tools, email, etc., would capture the narrative in much the same way as for chatbots.
Once the data of the request is captured, it is fed to the classification AI. In the case of registering a request via the mediation of tools (chatbot, chat, email, self-service portal, etc.), this would be done automatically. In case the human agent registers the request manually, the triggering of the classification could be manual or automatic, depending on the type of integration and the interfaces in place.
Finally, the AI arrives at a classification and its associated confidence level. Given the probabilistic nature of artificial neural networks, it might be a good idea to have a final confirmation step before recording the classification. This would be possible in any form of interactive contact with the service consumer, such as via a chatbot or a telephone conversation. The chatbot or the human might say, “This is how we have understood your request” and request some confirmation by the consumer that the classification is accurate.
I noted above that an AI will output a classification with a certain level of confidence. This means that each service provider organization must judge what level of confidence is sufficient for its purposes. This judgement depends on the organizational tolerance of risk, the trust it has in the technology and the skill with which the AI has been modeled and trained. This view of levels of confidence influences the particular way in which the AI is operated.
The final step is the recording of the classification. Depending on the level of confidence and the threshold established by the organization, this may be done manually or automatically. Typically, an automatic record would be made for high levels of confidence. For low levels of confidence, the classification would have to be referred to a human agent. There is probably a grey zone between the two, wherein the AI might suggest a classification, but a human agent might adjust it. In any case, human adjustments to the classification should always be possible, but it would be useful to record the fact that a human has overridden the AI. These data will be used during the continual learning phase.
Improving the AI
There are many reasons why an AI needs to continually evolve and improve, via some feedback and learning. Among the obvious reasons are changes to the services being offered by the service provider and changes to the types of support available, such as the support channels and the levels of service. More subtle are the changes to the consumers, whose skills and expectations may change over time; changes to the jargon in use in the organization; changes to the competitive position of the service provider and the need to improve its services.
It is also likely that the service provider will come to recognize the usefulness of data types that had not been collected at first. As a result, effort is invested in enlarging the data available for classification purposes. Furthermore, there might be improvements in the quality of the data available, such as more complete and more accurate configuration management data.
There are various types of data that should be logged, which data will be the basis of the improvement activities. I suggested above that classification should be confirmed interactively with the consumer, if possible. Cases where the consumer responds, “No, that’s not it at all” need to be recorded. This is prima facie evidence that the AI is not classifying correctly for the inputs it has received.
In some cases, records will be reviewed and adjusted after the service request is resolved. If the classification needs to be changed, given the full experience of handling the request, then this, too, should be fed back to the AI to make improvements.
Another type of data used to improve the AI is the record of rejection of assignments and reassignments of tasks. When a request has been misclassified and, as a result, assigned to the wrong team, this can be detected from the assignment records (assuming a push-type method is in use for managing the flow of work).3 This sort of issue is distinct from the problem of playing ping-pong with an assignment, which may indicate another type of problem, not necessarily a classification issue.
Feeling the effect of feeding back additional data depends on some parameters in the configuration of the AI, such as the “learning rate“. Essentially, this parameter adjusts the sensitivity of an artificial neural network to changes in training data. This, in turn, affects the time needed to train, the amount of training data required and even the effectiveness of training in converging on stable and reliable outputs.
Let me give an exaggerated example. An important question is how to weight the mention of a desktop computer name relative to the request classification. For some requests, such as adding a new screen or replacing a broken mouse, it might be extremely important. For other requests, such as restoring the backup of a file to a network drive, it is largely irrelevant.
Now, imagine the first training data set mentions a desktop computer name and the case is labeled as “Repair desktop computer”. The artificial neural network will decide that the computer name is really important. But suppose the next data set in the training data also mentions the computer name, but is labeled as “Restore file from backup”. If the learning rate is set too high, the the AI will think, “Oh, that last example was probably just noise. Instead, the desktop computer name seems to be a good indicator of the need to restore a file.” And so it can flip-flop back and forth because it is too sensitive to the changes in training data.
But suppose the learning rate is too low. If the first training example is labeled as “restore a file”, it might take a very large number of counter-examples before the AI finally converges on the computer name being a good indicator of a repair issue and a bad indicator of a file restore issue. So, the art of setting the learning rate, which is a technical task under the responsibility of the data scientist, can influence the cost of the AI, its time to market and its effectiveness in improving the classification of service requests.
Communicating with Stakeholders
In the previous sections of this article I have portrayed the example of AI applied to service request classification. Certain communications with service request stakeholders should help to frame the expectations of applying AI to this purpose, justify its use and support the success of an AI approach.

Communicating with Service Consumers
Some service providers might believe that using AI is an end in and of itself. They believe that it is “modern”, “up to date”, “competitive” or perhaps even “miraculous”. While this sort of hype might be eye-catching and draw some attention, I am more concerned with the longer-term value-related issues that underpin a successful provider-consumer relationship.
Justifying the Collection of Data
The success of using AI in the management of service requests is likely to depend on the collection of data about the service consumers. If those consumers are external to the service provider, many countries require a great deal of transparency regarding what data is collected, how it is used, the rights of the consumer regarding those data and the responsibilities for handling the data. Thus, the service provider might be legally required to make all this information available to the consumer before the consumer engages in any transactions.
I believe that service providers also have a similar moral obligation toward its employees and contractors, even if no laws oblige such transparency.
Communicating Changes in Interfaces
I will treat the different communications channels separately: telephony; on-line self-service; and asynchronous off-line communications. The service consumer should probably not expect any changes in the nature of making a request via telephony. However, to the extent that the conversation might be subject to speech-to-text handling, the consumer should be made aware that the conversation is being recorded, as a precursor to the classification treatment.
The self-service interface might have a more significant interface change. Traditionally, self-service interfaces attempt to structure what is fundamentally an unstructured communication. Thus, consumers are sometimes led through a series of drop-down menus or other mechanisms to guide them through a complex taxonomy of choices. Such interfaces often have mixed results, largely because they are unnatural ways of communicating and they tend to view the information taxonomy from the service provider’s perspective rather than from the service consumer’s perspective. In the end, these interfaces only collect what the service provider wants to hear, rather than what the service consumer wants to say. As a result, much potential information about the request might be lost.
A more natural way of communicating is the free speech approach of the chatbot.4 By collecting data that the consumer wishes to communicate, the channel is less apt to filter out useful information. Too, it allows for disambiguation of speech, helping to identify key entities in the communication.
In some contexts, service consumers have been passively trained to communicate in a certain way to service providers. This bias may lead them to present what they believe the provider needs to hear, rather than what the consumer wants to say. Therefore, it may be important to provide signals to the consumer to be at ease, to not make assumptions about “right” and “wrong” information to communicate. Consumers should not try to manipulate or trick the system to work in the their favor.
Communicating with Service Provider Personnel
The introduction of artificial intelligence tools is often perceived by employees as a threat to the nature of their work, to their identities and, indeed, to their very employment. Managers often encourage such negative reactions by portraying technology introduction principally as a way of reducing FTEs.
As we have seen, AI cannot be used as an end-to-end tool for providing or managing services. Today, AI can only respond to limited and well defined purposes. The major benefits of AI in service request management are in reducing lead times, reducing errors, increasing the satisfaction of all stakeholders and possibly reducing costs.
As a result, any initiative to introduce AI into the management of service requests should start by identifying what the support personnel believe they need to improve the performance of their roles. Framed in this way, AI becomes a tool the existing personnel use to do their jobs better and increase their satisfaction in their own work. Support personnel remain the masters of their work, rather than being subjected to “improvements” by people who lack the experience of working on the front line to support the service consumers.
Except for the simplest and most obvious of cases, classifying service and support requests can be hard to do and takes a lot of time to perform correctly in a high pressure atmosphere. The purpose of AI is thus to help the support personnel to perform a task with which they have difficulty. Communicating this fundamental message to the support personnel will help reduce the antagonism with which many people greet imposed change. Instead, introducing AI is viewed as evidence of concern for the employees’ well-being and investing in their capabilities. As the saying goes, it is not that people dislike change; they dislike being changed.
Communicating with Management
If, as they say, “AI is the new electricity”, then it is critical for the perdurability of the service provider organization to gain artificial intelligence capabilities. But AI for the sake of AI is sterile; it cannot be an end unto itself. The business purposes of using any AI tools must always dominate any communications with the service provider management. At the end of the day, AI must provide economical solutions to real business problems.
Communicating with Regulatory Authorities
Certain businesses are heavily regulated, due to the close relationship between the outputs of those businesses and the health and safety of its customers and of the environment at large. In a world accustomed to thinking in deterministic terms, how easy is it for regulators to accept a management system based on statistical learning?
Take the example of the manufacturing of pharmaceutical products. Given the risks to patient health of medicines that do not conform to authorized specifications, the entire manufacturing system, including any changes to that system, is subject to regulation (at least, in many countries). It is required that calibrated tools used according to a known and authorized process, be used to reliably produce drugs of an acceptable level of quality.
Now, imagine that we introduce into that system a technology that does not claim to work in a deterministic way, but in a probabilistic way. Will that technology be acceptable to the regulatory authorities? If they ask you if your system will guarantee the health and safety of the consumers, will they be satisfied if you respond, “Yeah, probably”?
Until such time as a technology becomes a generally accepted practice that does not require ad hoc authorization, the users of AI should be sensitive to this issue in communicating with regulatory authorities. I think the best approach to take is to demonstrate a lower defect rate when using AI. In fact, the real issue is the belief that other systems are not probabilistic. In fact, all information systems and manufacturing systems have a probabilistic aspect.
Conclusion
In this article I have attempted to instantiate my proposed model for using AI for service management. I have used a simple example that should be familiar to most service managers. Each phase in the life of an AI, as described in that model, has been discussed in some detail, illustrating the principles involved. It is now up to you to apply those same principles to other cases where AI might help you to better deliver and manage your services.
![]() The article AI for Service Request Management by Robert S. Falkowitz, including all its contents, is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
The article AI for Service Request Management by Robert S. Falkowitz, including all its contents, is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Bibliography
[a] Perrow, Charles, Normal Accidents. Living with High-Risk Technologies, Princeton University Press, 1999.
[b] Hubbard, Douglas, How to Measure Anything. Finding the Value of “Intangibles” in Business, 2nd ed. John Wiley & Sons, 2010.
Notes
Credits
Unless otherwise indicated here, the diagrams are the work of the author.
Subscribe to our mailing list
Reader Interactions
This site uses Akismet to reduce spam. Learn how your comment data is processed.
Leave a Reply