BPMN: a step toward automation
I have argued elsewhere that the typical service management tools in use today might be suitable for service desk agents, but are annoying, redundant and of little value to anyone else involved in resolving incidents, among other activities. I have further proposed that existing IT management should be leveraged to automate much of the work, rather than layering a ticketing tool on top of them. In this article I will describe the use of BPMN notation for an incident resolution process as a small step in that direction. In addition, BPMN helps to narrow the chasm between the process flow diagram and the reality of the practices.
Traditional diagrams are too complex!
Anyone who has tried to model the interactions that occur during the management of an incident may be frustrated by the great complexity of “traditional”1 process flow diagrams. Ironically, these same diagrams use a notation is supposed to be simple enough for anyone to understand them. But the reality is quite the opposite. They are complex, inelegant and off-putting to anyone except die-hard process modelers. Often, they are more of a reification or a gestalt than any real attempt to manage anything. The notation used is not well adapted to the reality of how incidents are managed.
Take, for example, the common practice of waiting a certain number of days for end user feedback after an incident is resolved, after which the incident is closed automatically. That feedback often does not arrive at all. The problem with traditional flowcharts is that the waiting is modeled as an activity, for lack of any other way of showing it. This gives the impression of a thumb-twiddling activity, which is hardly the case! Compare Fig. 1, with three activities and two decisions, to Fig. 2, where the same flow is modeled with a single activity and a series of events that might occur during the performance of that activity.
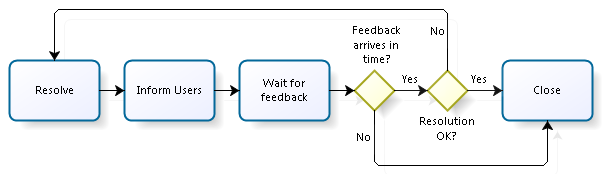
BPMN makes diagrams simpler, but more complete
By leveraging BPMN notation, we simplify greatly the depiction of the interactions during the work. Furthermore, the formal rigor of the notation allows us to set the stage for automating much of the activity. Using the same example as above, traditional notation fails to model what is often the reality of resolution as an interactive procedure, simultaneously involving both the resolver and the user. It depicts a process where everything happens in serial fashion. BPMN can model this simultaneous interaction with no difficulty. To paraphrase Einstein, BPMN helps make the diagrams as simple as possible, but no simpler.
BPMN documentation of incident management
Here is a possible diagram for incident resolution (see Fig. 2). It does not attempt to document absolutely everything that occurs during the resolution of an incident. However, it should be clear how additional elements, such as the consultation of knowledge bases, monitoring tools or configuration management tools, might be documented. Note that the incident resolution process is only the lower pool. The upper pool describes what happens in the customer’s process when an incident occurs. This use of separate pools is another strength of BPMN. The interaction among processes is clearly documented.
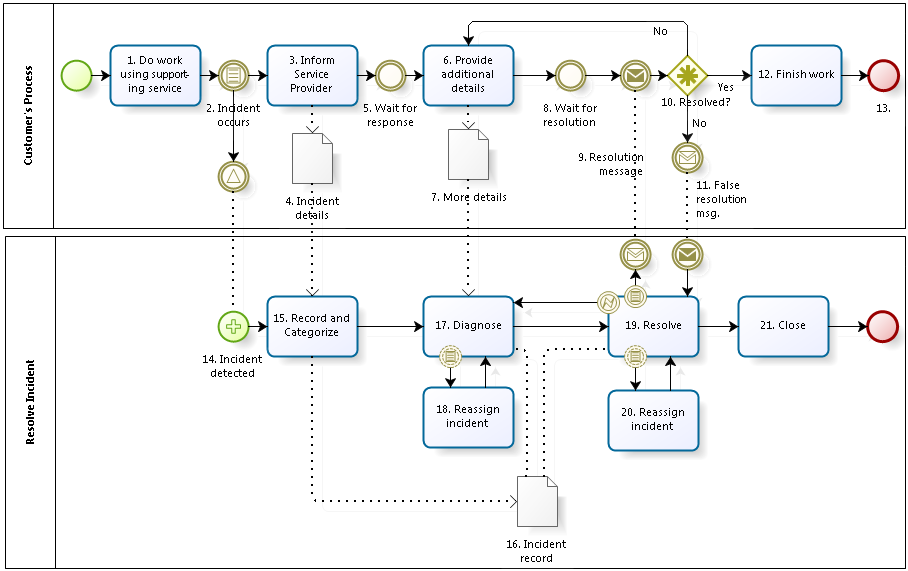
Let me talk you through the events and activities.
We start with the customer doing some work [1] with the support of a service from the service provider. Then, an incident occurs [2]. Note that the incident is understood as an event that blocks the user from continuing his or her process as desired. It is not modeled as a defect in the IT system used to deliver the service, even though such defects are typically occurring upstream. The incident is signaled to the service provider, where the reception of the signal triggers the service resolution process [14]. (I have not modeled the detection of incidents via monitoring systems internal to the service provider.) In parallel, the impacted user informs the service provider [3], providing various details about the incident [4]. That information could go through any number of different channels. Furthermore, that communication may itself be the second part of the signaling event that triggers the process.
The service provider records the incidents and performs some initial categorization [15]. The output of this is an incident record [16] (which may have been created automatically or manually, depending on the channels used to communicate the event and the degree of automation in place).
While the customer is waiting for a response from the service provider [5], the service provider starts to diagnose the incident [17]. Several things might happen during the diagnosis. First, the customer might be asked to provide additional details [6]. Second, the service provider may consult and possibly update the incident record [16]. Additional data might be received from telemetry (not shown in the diagram). Finally, the person doing the diagnosis might become blocked. This blockage is shown by the border event in the Diagnose activity ![]() , which leads to the re-assignment of the incident to someone more apt to do the diagnose adequately. This is a conditional event, meaning that it is triggered when certain conditions are fulfilled. A typical set of conditions for functional escalation would be: lack of knowledge or lack of access rights. When triggered, the process flow follows the arrow leaving the event. Once re-assigned [as shown by the arrow from 18 to 17], the Diagnose activity continues [17]. From a BPMN perspective, the blockage is non-interrupting, meaning that the diagnosis continues (as opposed to a blocking event that results in cancellation of the activity). I have not shown the internal details of the diagnosis, such as the consultation of various tools, knowledge bases or other data stores.
, which leads to the re-assignment of the incident to someone more apt to do the diagnose adequately. This is a conditional event, meaning that it is triggered when certain conditions are fulfilled. A typical set of conditions for functional escalation would be: lack of knowledge or lack of access rights. When triggered, the process flow follows the arrow leaving the event. Once re-assigned [as shown by the arrow from 18 to 17], the Diagnose activity continues [17]. From a BPMN perspective, the blockage is non-interrupting, meaning that the diagnosis continues (as opposed to a blocking event that results in cancellation of the activity). I have not shown the internal details of the diagnosis, such as the consultation of various tools, knowledge bases or other data stores.
This way of diagramming functional escalation is much more elegant and accurate than the traditional method. We have all seen diagrams with extensive branching after the diagnosis activity, followed by reassignment to another activity (also called “Diagnosis”), but in another swim lane. And this is repeated for as many lines of support as the modeler has the patience to document.
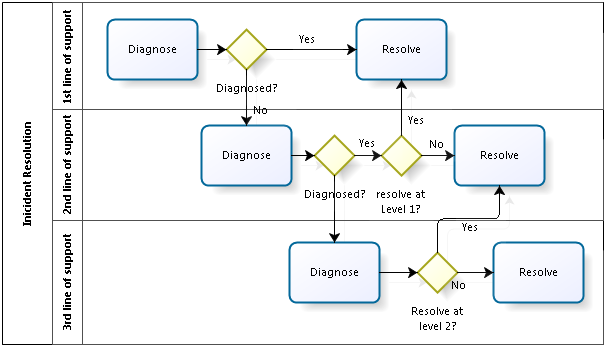
I hope you agree that the process flow in Fig. 3 is not only much more complicated than in Fig. 2, but it is also too rigid. We cannot always know in advance how many levels of support might possibly be involved. And sometimes it is reasonable to not follow a strict, lines of support escalation.
There is a further difficulty with the diagram in Fig. 3, albeit not really significant unless we try to automate the process. This diagram leads us to believe that in the case of a functional escalation, the Diagnose activity has been correctly completed. But this is obviously not the case. We fall into a “well, you know what I mean” situation. This is not the case in Fig. 2, where there is only one Diagnose activity and it ain’t over till its over. In short, the arrow leading away from an activity in traditional notation only indicates that that activity has stopped. It does not indicate whether the required exit criteria have been met. BPMN provides simple means for distinguishing between the successful and the unsuccessful completion of an activity.
This seemingly subtle distinction makes a world of difference when it comes to defining the metrics of a process and capturing measurements automatically. It is an important feature that allows us to directly relate process effectiveness to process efficiency. If we measure the lead time for performing an activity, a typical efficiency metric, the end of that activity (and hence the end point for the lead time measurement) is determined by the exit criteria for effectiveness, not by the simple fact of having performed the steps in the activity. Let me explain that very long, complicated sentence. Some organizations split the measurement of efficiency and effectiveness into two separate metrics. It is possible, according to this approach, to be very efficient and very ineffective. An example of this would be completing the resolution activities of an incident very quickly, only to find that it was not resolved and having to restart the diagnosis. I believe that effectiveness must be inherent in efficiency measurements. You measure however long it takes to do the work correctly.
Continuing with the narrative, we note that the diagnosis may profit from additional information provided by the customer [6,7]. After providing that information, the customer must wait for the resolution [8]. When the diagnosis is completed by the service provider, the resolution itself takes place [19].
Instead of showing a large number of decisions to handle any exceptions related to the resolution activity, in BPMN we can simply show border events (shown as circles embedded in the edges of the activity symbol). We have already seen the border event for functional escalation and the resulting re-assignment [20], which is identical in both the Diagnosis and the Resolution activities. The second event is the message sent to the customer when a condition is met in the resolution activity. That condition is, of course, that the resolver believes the incident is resolved [9]. The customer may then assess the situation and provide his or her own perspective on whether the incident is resolved. If not, a message may be sent back to the service provider [11] that the resolution was false. In this case, an error event ![]() is raised in the activity and the flow goes back to the Diagnose activity [17].
is raised in the activity and the flow goes back to the Diagnose activity [17].
If, however, all is well, the flow continues to the Close activity [21]. Some organizations may wish to show additional updates the incident record, output to problem management, or perhaps a request to the customer to rate the resolution service. I have not shown them here, but the notation would be similar to what we have already seen.
Benefits of BPMN Notation
We see that the use of BPMN notation allows a diagramming of the process with no “decisions” or branching, making the overall diagram much, much simpler. In spite of that, we see all the essential communications with the customer (which are often missing in traditional diagrams), as well as the functional escalations and the input to and output from the incident record. The events occurring during the Resolve activity are summarized in Table 1.
| Event | Event Type | Action Triggered |
|---|---|---|
| Incident diagnosed | Process flow | Resolve the incident |
| Incident resolved | Process flow | Close the incident |
| Resolver cannot resolve | Condition | Escalate the incident |
| Incident escalated | Process flow | Continue resolving the incident |
| Resolver believes incident is resolved | Message | Inform users of resolution |
| User informs resolver that incident is not resolved | Message | Determine if the issue concerns incorrect application of resolution or incorrect resolution |
| Resolver determines that the resolution is incorrect | Error | Return to incident diagnosis |
| Incident status changed | Artifact update | Update status and other details of the incident record |
Table 1: Events and resulting actions during the Resolve activity
There is no branching in the process flow, which should be reserved for cases where there is truly a different way of handling the work. We easily see the points at which the process requires waiting. This waiting is, of course, anathema to any lean way of doing work. So the diagram readily supports a lean analysis potential improvements. Finally, there are many tools on the market today that can fully or partially automate work directly from the process flow diagram. Not only that, such tools can readily simulate the process, showing its performance under a variety of conditions and distributions of events. This is quite impossible when the diagrams are drawn using presentation or drawing tools.
Some might object that process flow documentation using BPMN is simply too complicated for most users. In my view, BPMN is simply one of the tools of the trade for anyone who pretends to be an expert in designing and optimizing processes. As for the process practitioners, it is true that some of the notation might look strange. But do these practitioners really use such diagrams? No matter what the diagram, these actors must always have some explanation of the tasks to perform in a process, the rules to be followed and how to use the supporting tools. When given such explanations, the novelty of BPMN notation is largely irrelevant for such people.
In resume, we have much to gain by documenting service management processes using BPMN:
- Simpler presentation
- Modeling closer to the reality
- Standard notation
- Support for lean analysis
- Process simulation
- Process automation
For further information…
If you are interested in using BPMN notation, here is some additional information. The notation standard is maintained by OMG, the Object Management Group. Here is the formal specification of BPMN ver 2.0. There are many tools available for business process management and for diagramming that implement the BPMN standard. Most of these tools combine some form of BPMN tutorial together with information about how to use it with the tool. Some of these tools, which may be free, also also you to simulate processes under various conditions, which is a great way to test your hypotheses about process optimization before you try them out in reality.
You can use BPMN notation reproduce, in its simplest form, to reproduce the simple flow diagrams you might already have. This is a complete waste of your time. If you want to use BPMN, then you should learn about how its features help you to simplify greatly your documentation, while making it much closer to the reality of what happens.
If you are interested in the symbology of Fig. 2, a convenient one page explanation may be found here.
![]()
1By “traditional” I mean the set of symbols that one finds in most generic drawing tools under the “flowchart” rubric, together with the “common knowledge” approach to how to use those symbols.
2I have shown the process in this way, as it is easily recognizable by most readers. I do not mean to say that I believe the process ought to work this way. Such a vision of incident management assumes that diagnosis and resolution are really two distinct tasks. This might be the case if an organizational purposefully assigns them to separate organizational units. But I believe that the process would be much more effective if a single team, containing all the people required to resolve the incident, were responsible from start to finish. In such a case, diagnosis and resolution would be more effectively modeled as part of one and the same activity, performed by a single role. As a result, the process diagram could be made much simpler, by a) eliminating the error event in resolution; b) conflating diagnose and resolve; and c) representing functional escalation only once, not twice. I would furthermore assert the heretical opinion that closure should not be part of the process. I would segregate the pure incident resolution activities from the follow-up activities that might send signals to problem management or knowledge management, manage customer satisfaction, or perform any of the other incident handling activities that might occur after resolution.
Hi Robert
Let’s assume that in Fig 2 the customer is Robert who comes to a hotel room. The incident is an air conditioning unit which makes an unpleasant noise. My guess is that you would not be a happy customer if you were treated with the incident management process. Instead there should be a customer service process, which would give you a new room or something. I think ITSM should see the need for customer service.
As I mentioned at the bottom of my contribution, I presented that particular version of a process because it is familiar to many people. I do not espouse it or pretend that it is the best way to work. Your suggested way of working, Aale, may very well be better, but I prefer not to address that question here. The focus of the article was completely different.
You are right of course but this raises another question. What is the benefit of documenting a process which is wrong. I have a suspicion that most of the ITIL processes are wrong and almost all process documentation is useless. Actual work happens outside processes and the recording is often done afterwards, just to please management, not to improve work. In your other document, you complained about the quality of ITSM process data. I have seen the same.
I don’t disagree with your implication that many organizations have very low capabilities when it comes to managing how people work. I think this is due, in many cases, to trying to manage at a high level, such as via the definition of a process, when the underpinning fundamentals are not in place. So, whether a process is “right” or “wrong” is not the question for me (and I hardly know how one can make such judgements). The question is whether the process, as used, is useful. And we all know that any attempt to model an activity using something written on paper or in a diagram, will frequently fail to express the reality of what happens, or even the reality of what should happen. Does that mean the whole exercise is useless? I do not adopt that counsel of despair. But first, an organization needs to have mastery of such basic things as how to manage the flow of work, what is the proper role of a manager, understanding the purposes of the different activities performed and knowing how to measure if those purposes are being achieved. Next, you have to decide if you really want all instances of a given activity to be performed in the same way. Sometimes the answer is yes, but very often in knowledge work the answer is that we cannot know in advance how to achieve the goals of the activity for any given case. We can know various patterns of work and we discover as we do the work how to apply those patterns.
Once the fundamentals are in place, a documented process model can be useful,especially for those activities that we truly want to standardize to a high degree. This is especially true when it turns out that counter-intuitive approaches give far superior results than might otherwise be achieved. The model helps us to simulate those approaches and demonstrate their feasibility. Furthermore, as soon as we try to fully automate work, the documentation can serve as a control for the automation, insofar as the documentation uses a formal notation, such as BPMN.
As of the quality of ITSM process data, there are many reasons for this. As you point out, there are strong biases present when people manually record data. But we cannot centralize such measurements in the role of a specialist, such as a ship or an airplane might assign measurements to a navigator. And I think that we would be fighting a losing battle if we try to overcome all those inherent psychological traits, such as Kahneman and Twersky have identified, that underpin many of these biases. As I have argued elsewhere, many of these biases can be removed by having the processes executed, and as a result measured, in much more automatic ways.
There is another source of “bad” process data, which is the assumption that by optimizing our investments in individual resources, we improve the overall performance of the processes in which they are used. So, we often end up measuring individual resource use and fail to relate that use to the goals of the activities being performed. This leads to such perverse reasoning as, “My team is being kept busy at 100%, so the poor performance cannot be my fault.” This is simply wrong thinking, but it underpins our measurements of processes that worse than useless – they lead us astray.
Hi Robert,
I was impressed by your article, and i agree fully with what you are writing. The future for ITSM-tools lies with BPM, where BPM will offer automation, processes which also can execute (and not only documentation), allignment between IT and Business is a common offering of BPM modelling, less techinical configuration and more process oriented, etc.
I would love to this dicuss this further with you. Please let me know next time you are in Belgium.
Best Regards,
/Guy
I would like to share with the audience, the fact that here in Mexico, I have used in different projects, BPM with ITSM. Is the best mix you can do in any implementation, the only concern here is that you need to advise the customers to take the easy way of BPM -only necessary stuff-. If not, then BPM or any other method w’ont be useful.
Greetings from Mexico. DMT
I have been documenting ITIL and business processes utilizing BPM process structures for the past seven or so years, so this is nothing new to me. I have found the best guide being ISO9001 as it defines all necessary requirements clearly. It aligns to business processes and enables the ITIL processes to be woven into the business processes where necessary.