










![]() The article Creativity, Quintessence and AI by Robert S. Falkowitz, including all its contents, is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
The article Creativity, Quintessence and AI by Robert S. Falkowitz, including all its contents, is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Notes:
1 See, for example, the work of Mike Tyka at https://www.youtube.com/watch?v=0qVOUD76JOg. See also https://mtyka.github.io/machine/learning/2017/08/09/highres-gan-faces-followup.html for a discussion of his method and https://mtyka.github.io/machine/learning/2017/06/06/highres-gan-faces.html for examples of work in progress.
Credits:
Fig. 1: By Jebulon — Personal work, CC0, https://commons.wikimedia.org/w/index.php?curid=45912325
Fig. 2: By Michelangelo – Public Domain
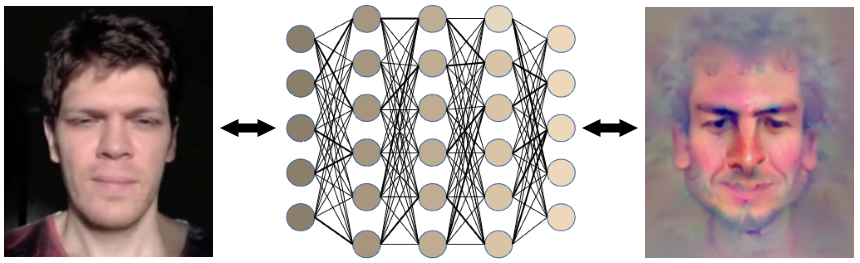
Fig. 3: Images of the face from https://www.youtube.com/watch?v=uSUOdu_5MPc
Fig. 1: By Jebulon — Personal work, CC0, https://commons.wikimedia.org/w/index.php?curid=45912325
Fig. 2: By Michelangelo – Public Domain
Fig. 3: Images of the face from https://www.youtube.com/watch?v=uSUOdu_5MPc
Fig. 5: By DickDaniels (https://carolinabirds.org/) – Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=17865691
Fig. 6: By Dario Sanches from São Paulo, Brazil – URUBU-DE-CABEÇA-VERMELHA (Cathartes aura )Uploaded by Snowmanradio, CC BY-SA 2.0, https://commons.wikimedia.org/w/index.php?curid=15173780
Fig. 7: By Dario Sanches from São Paulo, Brazil – MOCHO-DOS-BANHADOS (Asio flammeus )Uploaded by Snowmanradio, CC BY-SA 2.0, https://commons.wikimedia.org/w/index.php?curid=12665908
Fig. 8: By JJ Harrison (jjharrison89@facebook.com) – Own work, CC BY 3.0, https://commons.wikimedia.org/w/index.php?curid=16491051
Fig. 9: Downloaded from https://www.pinterest.com/pin/237424211579073442/?lp=true
Fig. 10: from https://www.youtube.com/watch?v=uSUOdu_5MPc
Fig. 11: Downloaded from https://www.secondwavemedia.com/metromode/images/Features/Issue%20126/DR-drportrait-240.jpg
Fig. 12: My own work, based on Fig. 11
Fig. 13: from https://www.youtube.com/watch?v=uSUOdu_5MPc
Summary
Article Name
Creativity, Quintessence and AI
Description
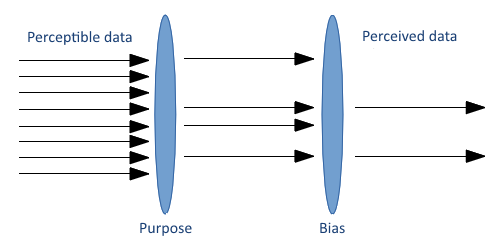
The current use of artificial intelligence to output images, texts, music, etc. does not qualify as creative. It does, however reveal the human biases that underpin machine learning and the quintessence of the output, as per the purposes of the designer of the system.
Author
Robert S. Falkowitz
Publisher Name
Concentric Circle Consulting
Publisher Logo
Dear Mr. Falkowitz,
I scrolled across your article and it was great reading it. I know a bit from computers and often people think of them as magic machines. But it is in fact processing “1”-s and “0”=s. Certainly not the way that human brain works, And this is the enigma. I personally suffer from bipolar depression and take medicine. It is said to me that the cause is disfunction of the hormone Seratonin which is called the hormone of happiness. I have talked with engineers and psyhiactrres and the later don’t have a clue how a machine works. They do not know how the electro chemistry in the brain works too. The medicine that I receive is based on empiric knowlidge, not technicly prooven. With a few words said, my sickness is sometimes that I feel too happy with no evident cause or too blue, again with no particular reason. Even the best computing machines that have self-diagnostic tools are merely doing math algoritams. The humans learn at best by immitating something, like learning to ride a byke, skiing, immitating math equotions, etc. I don’t think that AI would learn to immitate for quite a while, not in our lifecycle. Einstein beleived in God. Tesla beleived in God too, and that is the best tool to keep sain. When we don’t understand somthing we say – that;s Gods will. And yet, theres a lot that we do not understand!