How does a purely internal activity like configuration management add value to customers? Would a customer gladly pay you for your configuration management activities? Keeping your configurations under control is hardly value adding in the same way as, for example, increasing the utility of a service. And yet, good configuration management underpins virtually all service management activities. How do we resolve this conundrum? What could lean configuration management be?

Configuration management according to the standard frameworks
Before getting into the details of what lean configuration management might be, I first need to clarify how I understand the scope of configuration management in the standard service management frameworks. Although there have been various published discussions of lean configuration management, they are essentially limited to the specific practices of software development. I broaden the discussion here while at the same time relating lean configuration management more closely with service management practices.
The discipline of configuration management encompasses many different scopes and practices according to many different people. For those coming from a U.S. military background, configuration management is essentially what other frameworks consider to be change control.[1] It is fundamentally about keeping under control changes to configurations of tracked components, and secondarily about documenting those configurations, as they change. In the service management realm, change control and configuration control are split into two separate disciplines, although they are intertwined in an elaborate tango. Nonetheless, an echo of the change control responsibility of configuration management reappears in ISO 20000:2-2005: “…configuration management plan(s)…should include or describe…the configuration management processes to…control changes to the configurations”. But it surely does not make sense for one discipline (change management) to control changes to configuration items and another discipline (configuration management) to control changes to the configurations of service components. See further below on this confusion.
ITIL® groups together under the rubric “Service Asset and Configuration Management” a wide array of activities. It follows the general practice of distinguishing between any component of a service system, called a “service asset”, and the subset of service assets whose configurations can be managed individually, called “configuration items”. We see a similar distinction, for example, in the aviation industry, where only a subset of all the objects that compose an airplane are actually tracked and are under control—the so-called “hard time” components.
If the distinction ITIL makes between a service asset and a configuration item is lucid, the distinction made by ISO-IEC 20000 between a configuration item and a service component is muddied, if not downright obscure. A configuration item is defined as an “element that needs to be controlled in order to deliver a service or services.” The existence of unmanaged services puts the lie to this definition. Further on, a service component is defined as “[a] single unit of a service that when combined with other units will deliver a complete service.” That sounds much more like the definition of a software application function than anything else. Recognizing the fuzziness of such a definition, the standard continues to give as examples of service components, “Hardware, software, tools, applications, documentation, information, processes or supporting services.” But in ISO-IEC 20000-4:2010, the distinction between CIs and service components is largely lost when it proclaims the tautology that “The purpose of the configuration management process is to establish and maintain the integrity of all identified service components” (assuming that “identified” means the output of the configuration management Identify activity). Are we to understand then, that a configuration item is the same thing as an “identified service component”? Or are there service components that have been identified, but are not treated as CIs (as per ITIL)?
CobiT retains ITIL’s distinction between asset management (BAI09) and configuration management (BAI10) and speaks of “assets” and “configuration items”, dispensing with the concept of service components.
Patterns of configuration management
So much for the theory of configuration management in the frameworks. Out in the field, configuration management signifies many different types of responsibilities, activities and tools, as varied as there are service providers. Yet there are several patterns that appear to dominate the landscape:
In a traditional software shop, configuration management concerns the documentation and control of the code and the libraries used to create applications. Since the same repositories control component versions and are the sources of the code used to create deployable applications, there is little chance that only a partial selection of components are kept under control. (Although I suppose that truly creative engineers find ways of getting around this.)
In addition, the technical procedures for creating applications may also be components under control. In contrast, the platforms on which applications are created, tested and ultimately run are generally not within the scope of the “traditional” software developers’ configuration control. Either these components are under the control of a separate infrastructure team, or they are controlled only in the minds of the developers, or they are simply not under control at all. Components such as testing protocols are similarly controlled in an ad hoc way, if they are under control at all.
It might be noted that in many organizations, especially those influenced by the U.S. military, what we call today “change management” was, in fact, a part of configuration management.
Within the past 10-20 years, certain software developers have attained a continual deployment capability.[3] This capability implies that not only the software components themselves, but also the build procedures, the tests and the platform configurations are all part of an integrated management system. This system allows for highly automated, “push-of-a-button” releases. Thus, a developer can commit a change to code, create an executable and the environment in which it shall execute, run a comprehensive series of tests and qualify the result as releasable, even deploy the release to production—all at the push of a button.
Such high levels of automation depend heavily on the virtualization of platforms and environments and descriptions of the configurations of those environments that are detailed enough to create (and destroy) any given system in which the software executes.
While this capability may be applied especially for the development and test environments, nothing prevents it from being applied to production environments, too, assuming that the physical hardware is available and configurable as required. Unfortunately, we are not yet able to create networks and computers out of thin air.
A technical response to the unsatisfactory situation in the previous pattern is the installation of software that “discovers” and automatically documents system components. Such approaches make misleading metrics such as “percentage of components documented” look much better. But they fail in the realm of improving the management of services. This is largely due to the incomprehension of the data collected, the vast quantity of data collected and the complexity of the relations detected. While many of these issues may be addressed by complicated configuration and customization of the discovery system, discovery tools do not increase the motivation of the personnel to use the data.
But more importantly, there is a tendency to assume that the configuration documentation provided by discovery tools is sufficient to meet the needs of configuration management. Unfortunately, it is not. One of the key goals of configuration management is to keep the configurations of components and system under control and in an authorized state. This is impossible unless the authorized configurations of components and relations are documented, together with the actual configurations. No discovery tool can determine what is authorized unless authorized states are documented separately.
In this pattern, there are no configuration management links between the teams responsible for creating applications and the teams responsible for operating IT. Furthermore, each operations team maintains its own approach to configuration management and its own tools. In some cases, they depend on the data in the management tools to control configurations. This is common, for example, among network administrators or middleware engineers. In other cases, they rely on spreadsheets or similar semi-structured or unstructured documents to hold whatever configuration information they deem important. In most cases, when the configuration data is separate from the management tools, it is updated manually, as an afterthought, and only if someone has the time to do so. Multiple versions of the same data are common in this pattern, with no clear responsibility for ensuring the overall coherence of data.
In response to the confusion and lack of consistent authority that reigns in the preceding pattern, frameworks such as ITIL have recommended the creation of centralized, authoritative databases to hold configuration data. This pattern tends to have limited success because the personnel often have no clear understanding of how they will use the data in the CMDB. As a result, they are not motivated to maintain it. The granularity of the data is typically based on seat-of-the-pants estimations and theory rather than real use cases. Only a small percentage of components are documented, that documentation is not maintained in a timely way and the responsibility for documenting relationships between components is poorly defined, if defined at all. In general, the personnel are overwhelmed by the volume of data that could be documented.
In this pattern, the typical response to these difficulties is to centralize responsibilities for configuration management, by naming configuration managers and configuration librarians.
This pattern is merely an extension of the pattern described above under Continual Deployment. The pattern depends on the system configuration tools to document what configurations should be (the authorized configurations). These same tools are used to generate the systems themselves, thereby guaranteeing that the actual configurations correspond, immediately after an automated change is successfully implemented, with the authorized configurations.
In the current state of technology, this method of configuration control is possible if the components themselves are virtualized. For example, a virtual computing platform is not a metal and plastic machine; it is software running on top of a physical platform.
By including discovery functionality, the tools also allow for automated detection and correction of configuration errors.
In the patterns described above, I have focused on IT configuration management. There are many other domains with similar levels of complexity and constraints, such as in aircraft maintenance or in transportation networks. The same issues of lean configuration management apply there, even if the historical development of management patterns in those domains has proven to be quite different from IT.[4]
Getting to lean configuration management
A facetious wag might remark that many organizations perform an extremely lean management of configurations, in that they manage configurations little or not at all. Be that as it may, such organizations are likely to produce a large number of defects in their products, while failing to address the underlying configuration problems in any effective way. Putting aside such dysfunctional organizations, let’s look at how lean may be the various patterns described above.
The key issue in assessing the lean-ness of configuration management is whether the necessary activities are, one the one hand, made part and parcel of the value added work and performed by the same actors, or, on the other hand, whether configuration management and value added activities are performed as a separate process, by separate roles, fulfilled by separate people.
Let’s compare some cases.
Case of centralized CMDB update
In company A (see Fig. 2), it was decided that all CMDB updates are to be performed by a centralized configuration librarian. The reasoning was that the people who know and understand changes in configurations do not reliably update documentation in a uniform and timely way. Sound familiar? In other organizations, it is assumed that specialized and highly qualified engineers should not be spending their time performing lowly administrative tasks, such as documenting configurations.
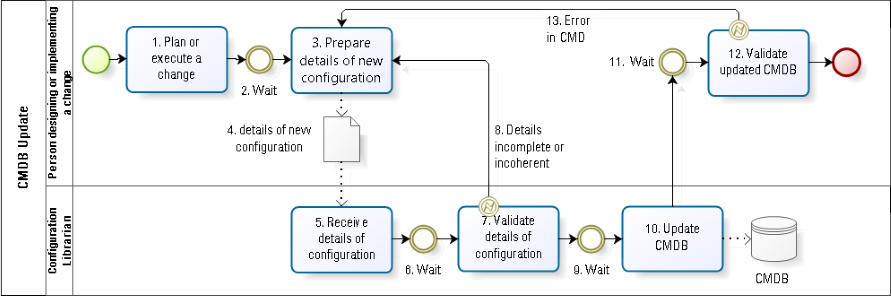
Suppose the configuration of a cluster of servers changes. The person designing the change must inform the configuration librarian of the new authorized configuration. The person executing the change must inform the configuration librarian of the actual new configuration (##3-5 in Fig. 2). The actual configuration after the change is not always identical to what was planned, for a variety of reasons, such as poor planning and poor execution.
In order to communicate to the configuration librarian all the information required to update the CMDB, the technical expert most likely needs to write down that information (##3-4 in Fig. 2). One must ask why it is possible to write down that information for the configuration librarian’s use, but it is not possible to write it directly into the CMDB? By splitting the update responsibility into two roles, various forms of waste are inevitably introduced: waiting before the communication is prepared (#2); waiting between the receipt of the update details and its validation (#6); waiting for the librarian to do the update (#9); waiting for the technical expert to validate the CMDB update (#11); errors or incompleteness in the information communicated to the librarian (defects) (#8); differences between the information received by the librarian and the information recorded in the CMDB (defects) (#13); or more information communicated than can be recorded (over-processing) (##7, 10).
Case of automated CMDB update based on a proposed change record
In company B, some of the issues faced by company A are addressed via technical controls and automation. One form of control calls for the change designer to document the configuration changes in a tool such that the CMDB is automatically updated when the change is deemed to have succeeded (see Fig. 3).
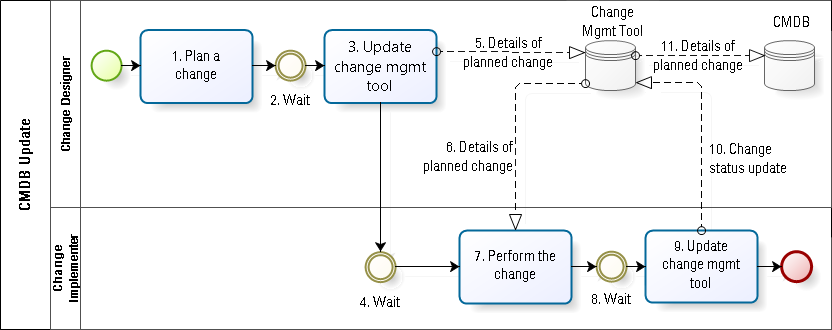
While this method reduces much of the waste found in company A, there are still various forms of waiting built in (##2, 4 and 8). In addition, it fails to handle the possible difference between the approved change (#5) and the actual change (which may be different from the details in #11).
Case of automated detection of changes, followed by reconciliation
A second form of control involves using discovery tools to document the actual change performed. This approach addresses the issue in the previous scenario (Fig. 4). There are potentially two parts to this automation (#9): the detection of the implemented configuration change; and the comparison of the detected change to the approved change. The issue of how to reconcile any detected differences remains an open question. In general, it requires an additional, manual task (#12). I do not expect reconciliation to be automated since, if such automation were possible, then the same tools would have automatically implemented the change, thereby obviating the need for reconciliation.
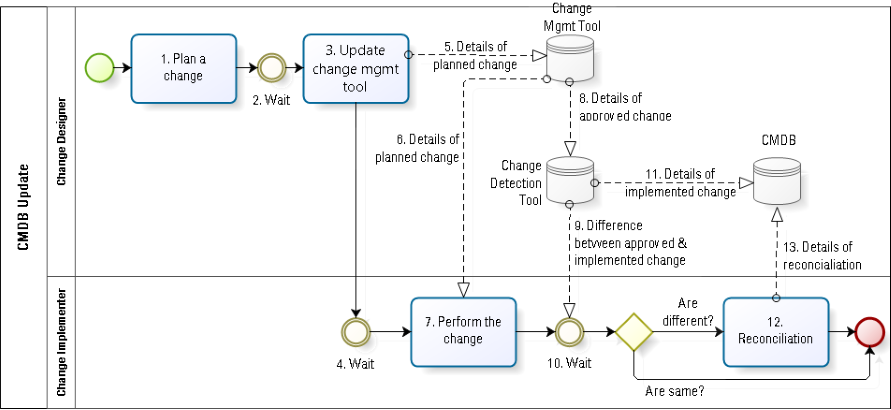
Note that even with this level of automation, there remain certain types of waste, especially if the change designer and the change implementer roles are played by two different people. There is almost inevitably some waiting during the hand-off from the designer to the implementer (#4). Note that once again I skip any reference to change control between the design and the implementation. I prefer to discuss in a future article the issue of change control in a lean environment.
Case of fully automated change implementation and configuration management
In the final case (see Fig. 5), company D has a layer on top of the physical infrastructure that can be entirely deployed and configured using templates and software configuration. The most common example of this would be a virtual computer whose characteristics are designed entirely in software.
In such cases, the tool used to document component and system configurations can be identical to the tool that deploys and updates those configurations. In a serverless environment—that is, one in which the physical server infrastructure is hosted entirely with third parties—the need for a CMDB independent of the software configuration and deployment tool is reduced to a strict minimum. Until such time as all premises equipment can be deployed and configured by a corps of robots, we will not be able to dispense entirely with a manually maintained CMDB. However, the day when the deployment tool in Fig. 5 would combine software configuration of virtual components and robotic configuration of physical components is probably not very far off. But until that day, the existence of the virtual layer on top of the physical infrastructure displaces a huge percentage of the configuration changes.
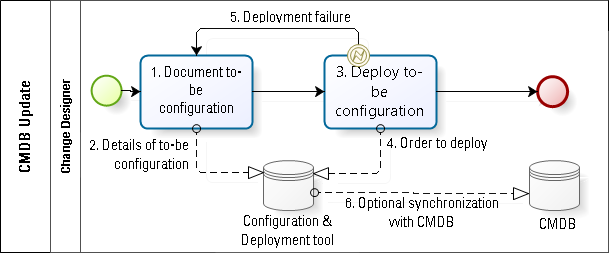
The procedure in this case is vastly simplified. The change designer describes the to-be configuration (#1), which is stored directly in the configu­ration tool (#2). When ready, the designer pushes a button to deploy the change (#3). If the change succeeds, the status of the to-be configuration is changed to an as-is configuration. If it fails, the system rolls back to the previous as-is configuration (#5). This approach to change deployment has a poka yoke characteristic, in that the only way to complete the change is to complete it correctly, as planned and authorized. There is neither any additional need to validate the change, nor to validate an updated CMDB, nor to reconcile a difference between an approved change and an implemented change.
The principal source of waste in this scenario would be in the design of the change (#1). It could be designed incorrectly (defect) or it could be designed with attributes that are not strictly necessary (over-processing).
I note that most organizations are likely to continue to need a place to document authorized configurations to cover the cases where the components are physical and cannot be deployed and configured via software.
Configuration management and necessary waste
The lean management framework recognizes the concept of necessary waste. Certain activities are not value adding from a customer’s perspective and do not significantly advance the transformation of inputs into the final product of a value stream. And yet, they cannot be eliminated.
The classic example of such activities are those required to demonstrate conformity to regulatory standards. I recently discussed with a former colleague from a bank how all banks are required to spend huge sums of money today to comply with the regulations of certain governments. In fact, that compliance sometimes goes directly against the interests of certain clients.
Nuancing the distinction between value adding and non-value adding
A harsh distinction between value adding and non-value adding activities, whether mandatory or not, lacks nuance. On the one hand, the customer is not the only stakeholder from whose perspective we should assess value. On the other hand, there are many activities performed by a service provider that may ultimately provide value to a customer, but which the customer might not recognize as such.
- Organizations operate within marketplaces.
- They use inputs and produce outputs that affect that physical environment.
- They have symbolic roles active in the realm of ethics.
A classic example of a necessary non-value adding activity to ensure the stability of a marketplace is the intervention of J. P. Morgan in the Panic of 1907. Following the failure of the Knickerbocker Trust Company, a major competitor of Morgan’s, he convinced his surviving competitors to inject capital into the market to shore up confidence in the marketplace and prevent a pernicious domino effect.
Many organizations perform activities to ensure that their outputs comply with environmental pollution standards. By so doing, they help ensure the long term health of the world and the continuing long-term operations of the organization. And yet, many customers would explicitly reject the need to pay for such activities. Thus, activities can add value to the broader eco-system rather than to the individual products it creates. And this, whether a customer recognizes it or not, whether the customer would gladly pay for it or not.
Risk management activities are a broad area where the value of the activity might never be recognized. Often, it is only in their omission that customer’s recognize their value. How many passengers on the Titanic would have gladly paid a higher ticket price to strengthen the hull of the ship to resist the impact of icebergs? Unfortunately, those who perished in its sinking were in no position to change their minds about such a need. Thus, customers may sometimes recognize the need to pay for certain activities, but only well after the purchase is completed. The buyer of a sports car might gladly pay for the power of the engine, the quality of the paint job and the styling of the body. But after an accident, that driver might thank his or her lucky stars that the vehicle had extensive airbags installed, an option that might not have seemed important at purchase time.
Configuration management performed as a kanban class of service?
The concept of delayed added value has its parallel in kanban’s method of applying classes of services to work. The intangible class of service—that is, a class of service where the initial cost of delay is not tangible and thus not something a customer would readily recognize as valuable or worth paying for—refers to work that is often absolutely critical in the long term. How many customers would ever willingly pay for the replacement of a provider’s network of coaxial cables by a system of structured twisted pair cabling? And yet, without performing such intangible class activities, the provider would ultimately go out of business. If all such providers went out of business, where would that leave the customers?
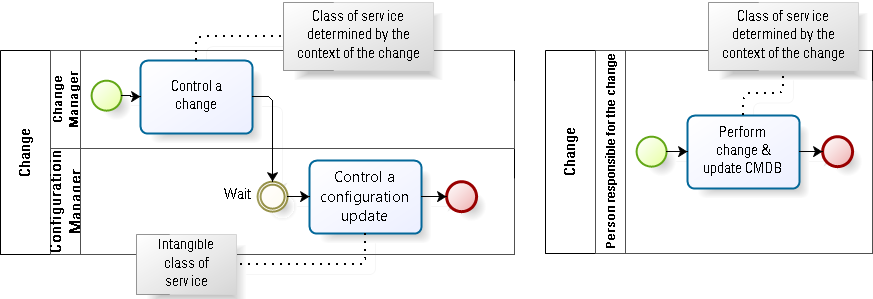
A warning, however. The concept of applying the intangible class of service to configuration management activities is appropriate only if those activities are performed as separate and distinct activities within the value stream (see Fig. 6). However, as we saw above, such an approach is hardly conducive to lean configuration management. I suggest a lean configuration management approach would embed the configuration activities within other activities in the value stream, rather than treat them as separate activities or a separate value stream. See the following section for more details about this embedding.
In summary, I hope you do realize that many of the activities we perform to manage configurations do, ultimately, add value, even if they would not be recognized as such in a classical lean analysis of value addition.
Assessing the lean-ness of configuration management activities
We have seen in the above analysis that there is a place for configuration management is the context of a lean management framework. But that does not mean that all the activities performed under the rubric of configuration management are equally valuable in a lean approach. Furthermore, some of the methods for achieving the valuable goals of configuration management might be considered as lean, whereas others are very wasteful. Let’s review the activities described in the traditional frameworks.
I refer to the discussion of planning as part of my analysis of release management. The same principles apply to configuration management. To the extent that any planning is required, in a lean context that planning would be subsumed under the overall lean implementation and the continual improvement activities.
As Einstein said, “In theory, theory and practice are the same. In practice, they are not.” So it is for the planning of configuration management, even in organizations with a command and control, waterfall approach to doing work. According to ITIL, management “decide[s] what level of service asset and configuration management is required for the selected service or project that is delivering changes and how this level will be achieved.” But this sort of planning is often wildly inaccurate, especially in organizations where the maturity level of configuration management is low. Simply stated, many organizations learn how to manage configurations by trial and error, not by “good” planning.
For ITIL, configuration identification is essentially the planning of how to control configurations. Ideally, this activity is performed with a clear understanding of how the controls will be used. But this is often not the case. Organizations discover, once again by trial and error, when components and relationships need to be identified and kept under control. As such, configuration identification is much like the planning and management activity.
In one organization with which I had worked, each team was given the responsibility for the naming conventions of the technologies they managed. It was only when the data was loaded into a CMDB that it was discovered that it was possible for a router and a Windows server to have the same name! Live and learn.
In my experience, organizations never get the granularity of configuration items right from the very start. It is only later, when they see that certain attributes are simply not maintained and are useless to them, or other attributes would be useful but are not recorded, that information granularity starts to approach a useful and maintainable level.
According to ITIL,
Configuration control ensures that there are adequate control mechanisms over CIs while maintaining a record of changes to CIs, versions, location, and custodianship/ownership.
There are really two separate “activities”: ensuring adequate control mechanisms and recording changes.
The former is one of those non-lean “ensuring” activities that I discussed at length in the context of release management. Of course, we do want the integrity of components to be maintained. But maintaining integrity is simply an approach to any of the value adding activities that involve the handling of components, such as the purchasing, reception, deployment and operational activities. It is not a separate activity, in and of itself. In a lean environment, an ensuring-type control is simply a policy according to which other activities must be performed.
The second activity, recording changes, is really at the heart of the lean configuration management conundrum. We surely must record this information, but what customer would gladly pay for our doing so? The virtual configuration pattern described above comes closest to performing this activity in a lean way. This is described in detail in the final case documented in Fig. 5.
I am not sure why ITIL groups these two activities together. In my view, status accounting is more appropriately grouped with the recording of component attributes, that is part of the control of systems and components, q.v.
Reporting of configuration information is inherently non-lean as a distinct activity. Does this mean that there should not be any reports about configurations? Of course not. It only means that the creation of a report is an activity that should be pulled by the customer of the report, on demand. It should not be pushed—created and distributed whether anyone wants to use the report or not—an approach that leads to the waste of over-production. In any case, reports of configuration are useful as tools in the context of other value-adding activities, such as the design of service systems.
Auditing is another activity that is inherently non-value adding, but may be necessary, either for regulatory compliance or as part of contractual obligations with suppliers of components, especially software components. As such, it may be difficult or impossible to eliminate all auditing.
Verification, like auditing, is inherently non-value adding. However, unlike auditing it cannot be justified by the need to comply with externally generated obligations. Furthermore, when verification is performed by a role that is distinct from the role of component ownership, it thereby enshrines and perpetuates a non-lean role. Those promoting verification argue that individuals are unlikely to verify objectively and in a timely manner their own property. This is rather like saying that a pilot should not be the person to check out the airworthiness of the airplane she or he is about to fly. If the owner of a component does not have an inherent motivation to ensure the integrity of that property and its proper documentation, then who else has a better motivation? So the problem is not that component owners are inherently sloppy or forgetful. Rather, it is that people have been named as owner just to ensure that all components have owners, but there is no reality behind that appointment, no true understanding of what the role requires.
The fact remains that there are inevitably errors in the records of configurations. It behooves us to identify those errors, correct those errors, understand why the errors occurred and remove the underlying causes of those errors. Whether you call this problem management or continual improvement, there is no reason for imagining a distinct activity to achieve the goals of improving how we work to keep configurations under control. The important point is that finding errors and correcting them should be part of the mentality of every team member. It should not be considered as something performed by other people who specialize in finding out what you have done wrong. Thus, verification is much like quality assurance as a last step before delivery. The same arguments about why such QA is expensive and ineffective apply also to configuration verification.
Resolving the conundrum of lean configuration management
We may summarize this discussion as follows:
- Attain the goals The high level goals of configuration as defined the standard frameworks are highly desirable to attain in a lean context.
- No separate process
However, the traditional approach of independent configuration management activities and configuration management roles is conducive to various forms of waste. In a lean approach, these forms of waste are to be eliminated wherever possible. A good example of this approach is a highly automated continual delivery method in the software development life-cycle. - Embed configuration management activities The goals of configuration management are achieved by embedding the necessary activities within other, value adding activities and making those activities as mistake-proof as possible.
- Empower and responsibilize roles So long as configuration management is viewed as administrative overhead, rather than ensuring the stability and reliability of services, the discipline will remain ineffective and, at the very least, inefficient. Empowerment of teams and making them responsible for improving their outcomes is fundamental for ensuring good, lean configuration management.
![]() The article Lean Configuration Management: A Conundrum by Robert S. Falkowitz, including all its contents, is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
The article Lean Configuration Management: A Conundrum by Robert S. Falkowitz, including all its contents, is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Notes:
1 For example, MIL-STD-480, MIL-STD-481, MIL-STD-483. You may find a summary here.
2 I refer to the method originally described by Jez Humble and David Farley in their book Continuous Delivery.
3 Jez Humble claims to have been doing continual deployment already in 2000.
4 I have presented an overview of some of the key issues here.
5 The diagrams in this article follow pseudo-BPMN conventions. While the arrows are not really correct, I think their meaning should be clear.
Leave a Reply