Manufacturing and service processes—similar but not the same
As more and more organizations use quantitative approaches to managing their services and service processes, so do management frameworks such as Six Sigma or Lean-Six Sigma become more and more used. However, the quality methods in such approaches were first developed to support manufacturing. They concern how to measure and to improve processes that deliver physical objects as output. These same approaches are also applicable to processes used to deliver and manage services, but there are significant differences between the two. This article will look at some of those differences.
In particular, we will look at the differences relative to:
- the pattern of variation in processes
- the use of control limits
- the cost of delay and opportunity costs.
The distribution of variation for service processes
As soon as you are able to measure a process, or its output, with sufficient precision, you are able to detect variation in that process or in its output. In a manufacturing environment, variation is generally divided into examples where the variation is acceptable, indeed, inevitable, and variation that is unacceptable. The former variation is typically classified as “common cause” variation; the latter is typically classified as “special cause” variation. (If you are already familiar with these concepts, you may wish to skip the next three paragraphs.)
Suppose you are manufacturing screws and you have specified that the diameter of the thread, for a given size screw, shall be 4 mm, ±.01 mm. In other words, a screw with a thread diameter of 4.01 mm is acceptable. So is a screw of diameter 3.99 mm. But a screw of thread diameter 4.02 mm is not acceptable. You may expect that your manufacturing equipment will produce screws with a variety of different thread diameters. The vast majority of them will be in the range of 3.99 to 4.01 mm, and therefore acceptable (see Fig. 1). The variation in this range is typically due to common causes. Those causes might be an inherent looseness in the machinery, or a certain level of vibration, or perhaps expansion or contraction due to changing temperatures, and so forth. The sources of common cause variation are commonly called the 6 Ms.
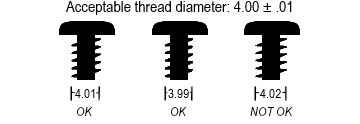
Screws with a thread diameter outside of the acceptable range are defective. These defects are generally due to special causes, which you should seek to identify and eliminate. The causes might include mis-alignment in the machinery setup, or a failure to lubricate on time, or a defect in the composition of the raw materials, or any of a large number of other possible causes. Note that special cause variation may be detected by patterns other than falling outside a set of limits, but this point need not detain us.
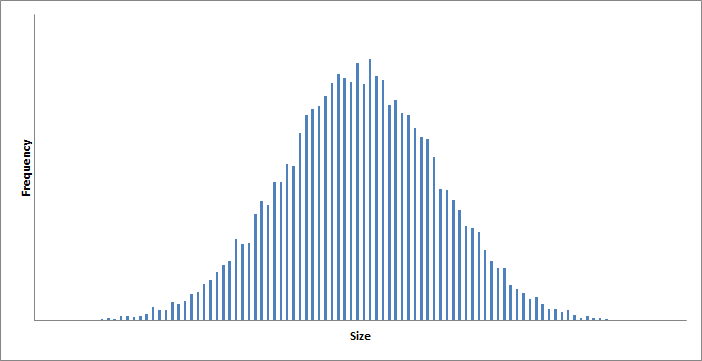
Experience has shown that variation in the manufacturing of physical objects typically has a normal distribution (see Fig. 2). That is to say, there is a mean value for the attribute being measured and the measurements are symmetrically disposed around that mean, becoming increasing rare as the absolute deviation from the mean becomes greater. In short, the distribution can be shown using a bell-shaped curve. The distribution of values around that mean is characterized by a statistic called the standard deviation.
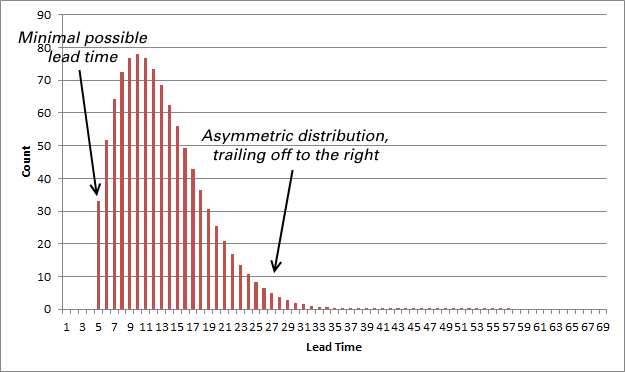
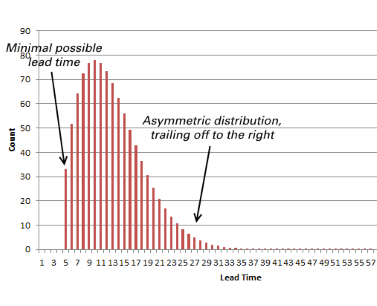
The distribution of measurements for a process that delivers a service is generally not the same (see Fig. 3). If we look at the most common metric for service processes, the lead time, we see intuitively that there are two simple reasons for this. First, performing a service act will always take a certain minimum amount of time. It cannot take less time than that. (At least, until some significant change to the process is made, it cannot take less time.) So the curve showing the distribution of lead times will not start at the minimum possible value for the service act duration, which is greater than zero.
For example, suppose you want to resolve an incident where a computer has crashed due to a memory leak. And suppose that rebooting the server is the fastest and lowest impact way to resolve this incident. Even if we were to instantaneously detect the incident and launch the reboot, it will always take a certain minimum amount of time before the server is available again and the incident resolved.
The second reason is that there is no theoretical maximum time for performing a service act. Unlike our example of screws, where the thread diameter can’t be greater than a certain amount, a service process might drag on and on, with no end in sight. And this certainly happens, for a variety of reasons. Sometimes, you lose track of a service and forget to complete it. Other times, all sorts of waiting are required before completing the work. Or perhaps you simply do not know how to perform the service and it takes a long time to figure that out.
So, the curve for the distribution of lead times will tend to trail off to the right, showing all those exceptional cases where the service seems to take forever. In short, the distribution is not a normal distribution, unlike in much of manufacturing. Instead, it tends to be skewed to the right.
This distribution of values may be modeled using a three parameter Weibull function. The chart in Fig. 3 shows a smoothed, idealized version of such a curve. Your own values are likely to be somewhat different. In fact, in my experience the data drawn from service management tools tends to be of very poor quality, with many missing or incoherent values. For example, those data are likely to have certain impossibly short lead times. I have even seen negative lead times! This is largely due to manual data capture that is out of control. Another factor leading to a different chart is the inclusion of very different activities in the same data sample, yielding a multi-modal chart. For example, a diagram that mixes together two or more completely different types of service requests is likely to show an incoherent set of values.
Control limits for service processes
When we specify what is an acceptable measurement of an attribute, we normally fix the limits between which that measurement should fall. In the case of manufacturing, such as the screws we discussed above, those limits are typically set as a desired value, plus or minus some delta. Thus, we used the example of 4 mm ± .01 mm. That level of precision might be perfectly acceptable for one market. Another market, however, might require different limits, such as 4 mm ± .0001 mm. Whatever the limits, it is just as bad for the component to be too small as it is to be too large. We call these limits the upper control limit (UCL) and the lower control limit (LCL).
When speaking of service acts, this is not quite the case. When we speak of process lead time, we might imagine that only the upper limit is significant. We might take too long to perform a service act, but we can never take too little time to perform it.
For an organization whose services are barely under control—and this probably means the majority of organizations when the services are not fully automated—we might be satisfied with this simplistic view of control limits. In such cases, as we mentioned above, values falling below a lower control limit are probably due to biases in the measurement system, rather than true cases of super-human performance.
An organization that has gained control of its service processes should probably want to go beyond the simplistic approach described above. When we perform a service, we always make a trade-off between the risk of delay in performing the service and the risk of lost opportunities. More advanced organizations shall want to manage these two risks. Let me examine these two types of risk in more detail.
Cost of delay for service processes
A given service does not always have the same deadline, if it has a deadline at all. In some cases, the consumer of the service needs the output by a fixed date. Delivering the output sooner is of no benefit to the consumer, but delivering it later will entail a certain cost, or loss to the consumer.
In other cases, that deadline is immediate. The consumer is already losing money and needs the service act to be performed as soon as possible.
But in the vast majority of cases, there is no particular deadline for the service. All things considered, it is probably better to perform the service act sooner, rather than later. Furthermore, there is likely to be an acceleration in the increase in costs to the consumer if the service is not performed quite soon. In some cases, that acceleration increases indefinitely, like an exponential curve. In other cases, that acceleration slows and tails off, with the cost to the consumer stabilizing after a certain time.1
The point to retain is that a service provider shall want to measure how successful it is in meeting customer deadlines. From the perspective of customer satisfaction, this is more important than performing a service in some arbitrary amount of time.2 The naive service provider might adopt the strategy of performing services as soon as possible, to limit the risk of not completing the service by the customer’s deadline. But this strategy fails to take into account the risk that you might be performing a service much sooner than needed and thereby not have the capacity to serve another customer with a more urgent deadline. Thus, we need to take into account opportunity costs, too.
Opportunity costs and service processes
Assessing the cost of delay in performing service acts is an intuitively clear approach to deciding when to deliver services. But we should also take into account the opportunities lost once we commit to performing the service act. The concept of opportunity cost depends on the assumption that a service provider has a limited capacity to perform services. Once committed to delivering a service at a certain time, the opportunity is lost to do other types of work at the same time.
Let me illustrate this idea using an analogy. Suppose you are driving down a completely unknown road with your family. Lunch time approaches and you need to decide where to stop for your meal. Assume that you have no idea what restaurants will come up on the road ahead or in the neighboring areas. You want to find a place that meets your budget and is also suitable to the tastes of all members of your family. You start to see different options, but hold out for a better one. However, as time passes and you become hungrier and hungrier, you are less likely to hold out for the ideal restaurant. So, finally, you stop at an acceptable restaurant and have your meal. It was within your budget, but you had hoped to find a less expensive place. You finish your meal, get back in the car, and continue your journey. And not more than 500 m. down the road, you see another restaurant that costs much less and has exactly the food that everyone would have wanted to eat. Too late! You lost that opportunity by virtue of having chosen to eat earlier.
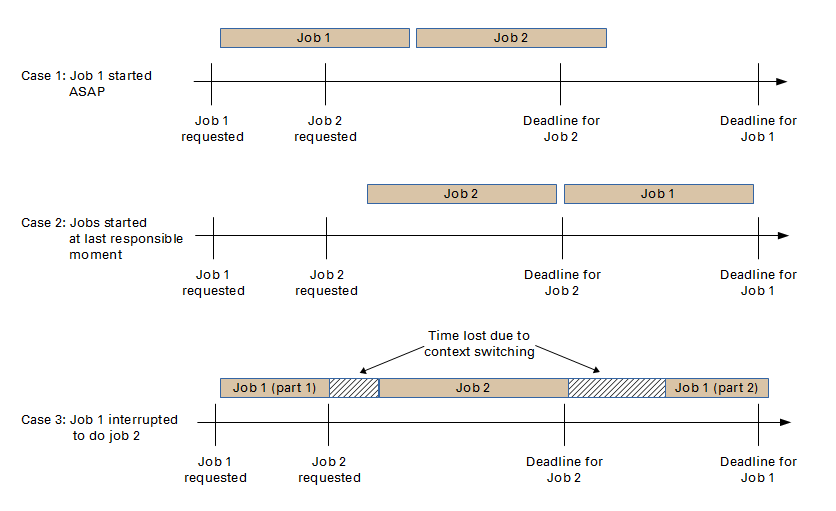
So it is with the delivery of services. If you start to deliver a service earlier than you really need to, you risk losing the ability to perform another service that you learned about only after starting the first service, one that turns out to be much more urgent for the consumer (see Fig. 4, case 1). And this is precisely what happens in typical situations, because the cadence at which requests arrive is largely unpredictable. The longer you hold off on committing yourself to performing a service, the lower the risk that another, more urgent, service request would come up in the meantime (see Fig. 4, case 2).
Some might say that this situation is easy to handle. All you do is to put the first service on hold, perform the second service, and then return to the first service. Well, it turns out that this approach is the worst of all possible worlds (see Fig. 4, case 3). As a general strategy, it increases the context switching between services that slows everything down. In the worst cases (which occur all too frequently), you fall into a vicious spiral where the only way to get anything done at all is by expediting a request.
So how should control limits be set for the processes that execute service acts? Let’s examine the lower control limit first. In the simplest case, an organization attempts to manage neither opportunity costs nor the cost of delay. In this case, there is no point in defining a lower control limit, other than the theoretical minimum time required to perform the service. In this simplest of cases, largely unmanaged and therefore not optimized, finishing sooner is always better.
At the next level of management, the cost of delay is taken into account. When cost of delay, by itself, is being managed, the benefits are essentially in the area of prioritization of work. The method gives a strong economic basis for deciding what to do next.
Finally, when opportunity costs are taken into account, we make the assumption that an organization running near to full capacity should not always commit to performing service acts as soon as possible. Instead, services should be put off until the last responsible moment. In other words, the organization should commit to work at the last moment possible, such that the work will be completed on time. In such cases, there is such a thing as starting the service too soon. It will be important to distinguish between, on the one hand, the lead time from when the service is first requested until it is delivered and, on the other hand, the cycle time from when the service process first starts until the service is delivered. Our objective is always for the cycle time to be as short as possible. But the mean customer lead time should be somewhat longer than the cycle time, to take into account the practice of limiting opportunity costs.
The difficulty is that for any given case, you cannot know in advance when that last responsible moment will be. We can, however, make assumptions about the overall results and adjust the lower control limit accordingly. We can know for sure that sometimes we will regret having committed to work as soon as possible, because another, more urgent, job will have arisen in the meantime. We can delay commitment so as to start to catch some of those cases. We can never be sure in advance that we will catch any individual case. But we can improve the overall, average performance by introducing a delay. Given the right historical data, it would be possible to calculate, using Monte Carlo simulations, the optimum delay. However, given the difficulties in capturing that data, it might be better to adjust that delay pragmatically, periodically re-tuning the delay to maintain an optimal result.
Setting the upper control limit has a set of similar issues. When we apply cost of delay criteria to the management of work, we realize that the optimum situation occurs not when we complete the work as soon as possible, but when we complete a maximum of work soon enough for the needs of the consumer. “Soon enough” can occur at many different times, even when performing exactly the same service act. Hence, in case of expedited work, the upper limit is never soon enough. In the case of fixed delay work, “soon enough” will vary according to the deadline. Only in the remaining cost of delay patterns does the concept of a fixed upper control limit make any sense.
We may close this discussion by comparing this situation with manufacturing. Just as there are naive service providers, so there are naive manufacturers. In the latter case, they produce goods based on the principle of optimizing the investment in the production chain, independently of the demand for those goods. Such manufacturers hope that an inventory will always be on hand to meet unexpected demand. This practice has its parallel in service organizations where the principle goal of managers is to keep their employees busy, in the vain hope that overloading them with tasks will result in faster delivery of results. The exact opposite is true.
A just in time manufacturer resembles the service provider who takes into account cost of delay and opportunity costs. The manufacturing process is launched only when triggered by a specific customer demand and that process should be timed so as to start as late as possible while still delivering to the customer by the expected deadline.
![]()
1Note that I am referring here only to the consumer’s needs on a service act by service act basis. I am not at all referring to service level agreements. You might agree in advance to perform a service by a certain deadline, which is a separate question from how the consumers’ needs might change from service act to service act.
2I have considerably oversimplified the situation for the sake of keeping to the point of the discussion. Customer expectations and satisfaction are likely to be modulated by many factors. The Kano model is an example of the influence of product segmentation on customer satisfaction.
Excellent article!
Love your example with searching the right restaurant.
I am in a current discussion about adapting statistical process control for service management processes. Thank you!
Best regards
Thomas
Good article and I liked the approach. Greetings. DMT
Exactly what I face in handling service delivery when an engineer has to own more than one service request, especially when he is the most skillful, and more frequently while there is no other with nearly same level of knowledge and experience, when you explain the opportunity cost and cost of delay.
Also Case 3 Fig. 4 several times is the only “choice” I can make, but it is not the main point mentioned.
Thanks for sharing your findings.
I think you are raising two issues: inadequate resource liquidity and no limits to work in progress. I will talk about personnel resource liquidity in a future article (almost completed!), so I won’t go into any details here. The issue of unlimited work in progress, and the resulting context switching, is one of the fundamental issues that kanban addresses. Again, I won’t go into the details here. It is perhaps anti-intuitive to think that we can finish all our work more quickly by doing only one thing at a time, rather than trying to do everything at once. Think about computer processors. If you keep the load low, the performance is excellent. But if the load goes up very high (like 90%), the performance slows to a crawl. The same think happens when people are overloaded at 110% So, case 3 is indeed a choice, but it is never the only choice. But choosing one of the other scenarios requires discipline and the trust of your business partners.
Thanks Robert, I look forward to learning from your new articles.
I just thought of the cost of delay and opportunity cost in my previous comment, but you are right because I experienced inadequate resource liquidity and abundant works in progress too. I can say it is about lack of (adequate) human resource, which results from bosses who don’t want to add more at least until they see employees (very) busy all the time or hear customer complaints, or my failure to convince them to do so 🙂
Regarding kanban approach, I appreciate the value of single-tasking and many times enjoy working that way, however after understanding above situation, you know why I said “only choice”.
The problem of managers who try to keep people busy is well known and very common. They do not know how to manage in any other way. Perhaps the best way to convince them that there is another way to organize work is via a set of simulations or games that compare this way of working to working using kanban principles.
And those are usually who are interested more in fire-fighting than fire-preventing as well.
Simulation sounds good advice, I will do some searches however are more details about it given in your past or future articles?
In retrospect, you will find many published articles that talk about the differences between manufacturing and services. With hardly any exceptions, these articles are not talking about processes. They are talking about services (considering that manufacturing is merely a type of service that outputs goods, rather than service acts). While the points raised in these articles are often perfectly valid, they do not affect the processes themselves. This accounts for why most articles say that manufacturing and services are very different, whereas I say that the processes used are really quite similar.