First, a reminder about why processes are used

Perhaps the most important contribution of ITIL V2 to the realm of IT service management was its emphasis on working according to well defined processes. This contribution has undoubted merits, although its unthinking, blanket adoption has come under considerable criticism. Be that as it may, the fundamental argument of working according to well defined processes is four-fold:
- attempting to work in the same way for each instance of an activity allows that activity to be measured each time, and allows for comparisons and analysis of those measurements
- working in a process-oriented way enables the principle of perfecting via practice
- perfecting an activity makes it more effective, more efficient and more predictable
- the measurements of processes may be used to determine in what ways it may be improved.
Working according to processes implements a vision often described as “Taylorism” (see Taylor, Principles of Scientific Management, 1911). Frederick W. Taylor’s great contribution to the refinement of the industrial revolution was in methods for optimizing manual labor. ITIL®, as well as many other frameworks, has adapted Taylor’s approach to the work of processes used to manage services.
What is the problem with processes?
A well defined process, such as might be delivered in a business process management context, is highly predictable. There is a predictable order to its activities. Each activity has a predictable set of inputs and outputs. The resources to be used for each activities are defined in advance. For many types of work, this approach is perfectly applicable. And for many other types of work, it is not.
We have all faced the frustration of trying to get a service from someone who is following an approved procedure, but that procedure had simply not taken into account our particular need.
Processes are agile up to a point. The so-called “dynamic business process” allows for data-driven decisions that introduce considerable flexibility into formal process definitions. But they do have limits. Anyone who has tried to follow a four page, 8 column process flow document, which contains more decisions than tasks, knows that such theoretical models can hardly work in our daily reality. What I call “spaghetti processes” can be so fragile that they often fail.
Adaptive Case Management to the rescue
Adaptive Case Management is an approach to doing work that takes into account the unpredictability of the inputs and outputs from activities and the unpredictable need for and availability of resources. It shares with process-oriented work the definition of specific goals for the work to accomplish. For example, the goals of problem management may be defined as reducing the impact of incidents by eliminating their causes or by finding effective work-arounds to resolve the incidents whose causes are not eliminated. Whether one attempts to achieve those goals via a formal process or via case work, they remain the same.
In order to be effective, Adaptive Case Management (ACM) requires the concept of a “case”, a container into which all the information and knowledge used for resolving that case may be held. The method by which that knowledge is acquired and the goals achieved unfold as work on the case progresses. This is because we cannot know in advance what information will surface, at what time, and how it will need to be handled.

As such, ACM is a formalism that implements a vision espoused by Peter F. Drucker (see, in particular, The Age of Discontinuity, 1969). For Drucker, the work of advanced economies is essentially “knowledge work”, performed by “knowledge workers.”
These knowledge workers, then, are the people who collaborate to resolve the case and reach the particular goals of the activity. As you might expect, knowledge workers in IT, among other disciplines, are heavily dependent on tools that help retrieve the data, information and knowledge required, as well as tools to handle the cases themselves and to work according to the various patterns that have identified that help resolve cases. As with processes, ACM is also subject to various constraints, coming from the legislation in vigor, industry practices and internal company policies.
ACM, in spite of its relative youth as an approach, already has a rich literature and supporting media and professional associations to foster its development. See, for example, Keith Swenson et. al., Mastering the Unpredictable: How Adaptive Case Management Will Revolutionize the Way That Knowledge Workers Get Things Done, 2010 and Swenson et. al.,Taming the Unpredictable Real World Adaptive Case Management: Case Studies and Practical Guidance, 2011. What has become an annual web event, ACMLive (acmlive.tv), presents a combination of primers, theory and case studies. The Workflow Management Coalition (www.wfmc.org) is a rich source of information, events and persons interested in ACM. Numerous blogs and social groups, such as LinkedIn’s Adaptive Case Management, populate the web. Indeed, the concept of case management is now making its way into the IT service management universe.
How do we position processes and cases?
An early view of ACM considered it to be a reaction to the frustrations with Business Process Management, whose rigid implementation in process automation tools led to failures in more complex types of work. While this view of ACM is too narrow, it has nonetheless led some to think in terms of a binary opposition of processes and cases. Indeed, the basic works on ACM all take examples of different types of work, classifying them as either appropriate to execution via processes or execution as cases.

In my view, this polarization does not represent the reality of how we work. It fails to take into account three aspects of work: the level of detail at which it is analyzed, the degree to which it is innovative and the evolution of that type of work through time. By taking these perspectives into account, we see that cases and processes are more like poles in a continuum of practices, rather than being a binary opposition.
The more work tends to be innovative, the more it tends toward the type of knowledge work managed with ACM. The more that work is commonplace and routine, the more can it be performed as a process. Indeed, the most routine tasks are the most amenable to automation. Similarly, the more we look at work from a high level perspective, the more is it amenable to be described in process terms. However, when we drill down to the details of how to perform that work, it often is closer to ACM. (To be sure, work is not process-oriented just because it is viewed at a high level.) Some examples of these principles are apposite.
Example 1: The emergency rescue mission
The case of a search and rescue mission is cited by case management analysts as an excellent example of knowledge work that is not amenable to being managed as a process (see Swenson, op. cit., 2010). However, the diagram of this activity in Fig. 4 shows clearly that the full life cycle of the rescue mission can indeed be described as a process. Only the planning of the rescue, and perhaps its execution, are likely to be different in every case. When the ACM analysts describe the case, they focus only on these detailed aspects, which require all the knowledge that the mission members can muster.
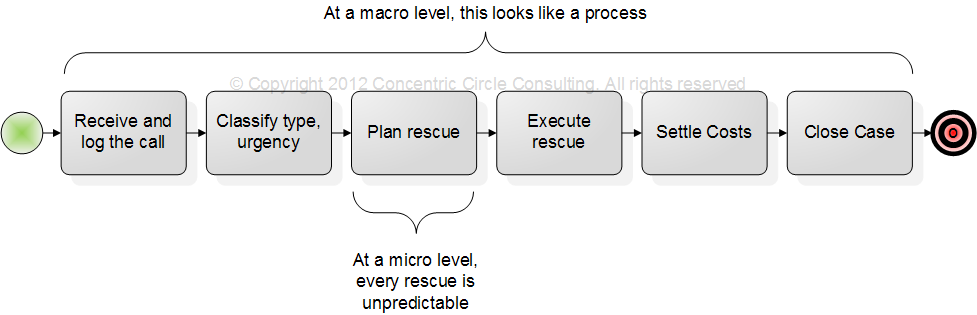
What about the scale from innovative to commonplace? In the rescue case study commonly cited, the head of the rescue mission was called upon to perform knowledge work when he discovered that the helicopter to be used could not carry all the people and equipment as planned. Some people might say that this is not an example of using knowledge; it is an example of inexperience and a failure to maintain control over the available “configuration items.” Be that as it may, the next time the same team was called to perform such a rescue, it probably did not make the same mistake. Indeed, a rescue organization with a broader geographical scope and one specializing in rescues is likely to learn from its own experience and from the experience of other teams, such that each succeeding rescue is done in a more and more systematic, process-like way. In time, such teams are likely to acquire more specialized tools that are better adapted to the rescue work.
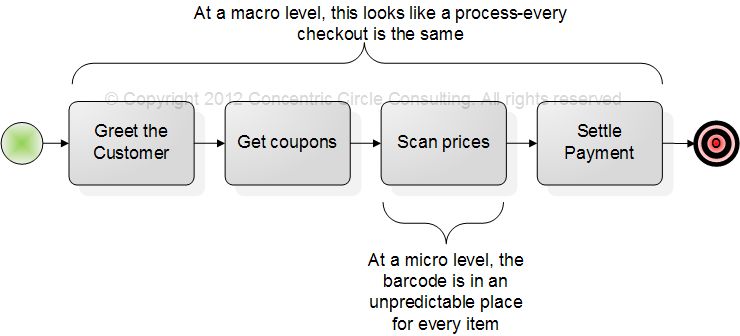
Example 2: Check-out at a supermarket
A customer check-out at a supermarket is cited by some case management analysts as an example of work that could hardly be more routine and that is an excellent example of work that can be managed as a process (again, Swenson, ibid.). Curiously, the same analysts dismiss the unpredictable aspects of finding and scanning price labels, calling this a “micro-level” that is not worthy of discussion. Granted that operating a cash register is less exciting than flying helicopters to rescue helpless people, but that does not mean unpredictable events, requiring a certain level of knowledge to manage, never occur. Ask this of any clerk who has had to face the problem of a dishonest customer trying to cheat the store. A friend of my daughter had exactly this problem last year. A group of crooks developed an innovative way to confuse the clerks and get back change for money they never handed to the clerks. Some clerks lost money, but others were quick-witted enough to recognize the scam. Finally, the store management generalized the practices of those latter clerks, adapting the check-out process to protect the clerks from the crooks.
Example 3: Supporting a user calling the service center
One of the most common examples of knowledge work given by the proponents of adaptive case management is the work of the call center agent. Every call from a customer is different. Every way of handling the call is different. They say that the way in which the call must be handled cannot be predicted in advance.
And yet, there is no organization that resembles a call center quite as much as a service desk, and no knowledge worker more like a call center agent than a service desk agent. Many IT organizations would agree that they have successfully implemented a variety of processes that dictate the way in which the service desk agents should work. There are processes for handling incidents, for complaints, for service requests and so forth. Why do certain ACM advocates ignore this reality? There are several elements to the answer.
First of all, some advocates of case management have a tendency to think of a process in terms of only those tasks that can be automated. They focus on those activities susceptible to automation and ignore the full life cycle of the case. Since we cannot fully automate the support of a user during a telephone call, they draw the conclusion that the work cannot be done in a process-oriented way. As a corollary to this, they criticize the attempts to reduce customer support work to a series of scripts—scripts which cannot possibly predict and handle all support situations. Secondly, they focus on very detailed aspects of the service desk agent’s work rather than looking at the broader context of the work. Most everyone is likely to agree that certain incidents, for example, cannot be resolved by applying a pre-defined model. They might require a diagnosis whose steps are not completely predictable in advance. Much of incident diagnosis is pure knowledge work. But that does not mean we should ignore the more routine steps of logging calls, classifying incidents, providing post-resolution analysis and clean-up and closing the incident.
Example 4: IT problem management
One could hardly name a better example of knowledge work than resolving problems. Problems are unpredictable. We cannot know in advance how they will be solved (else they wouldn’t need to be handled as problems!). The steps required to find a problem’s causes often emerge during the analysis. But again, many IT organizations have adopted a problem management process, with a clear set of pre-defined steps to follow, no matter what the particular problem might be.
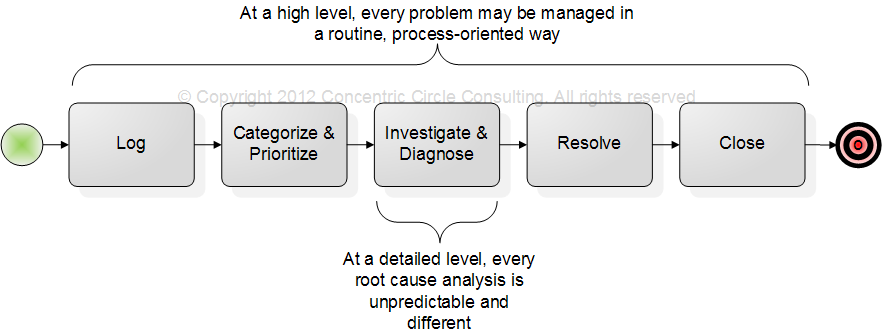
Even the investigation and diagnosis of a problem is not done starting from a blank slate. The mature problem manager has a full tool kit of techniques to apply to structure and move forward the diagnostic work by the subject matter experts. Many of these techniques are themselves highly structured and process-like.
Signor Pareto meets the Knowledge Worker

The ACM proponents make a strong case that the special characteristics of knowledge work require an approach that is difficult to automate. This might be true at an early moment in the history of a certain type of work in a certain organization. However, we should take a dynamic view of the evolution of knowledge work. Each case that is solved becomes a source of knowledge that may be applicable to other cases. As the diversity of cases becomes known and as that knowledge accumulates, it becomes possible to manage certain types of cases in a routine way. This is a standard approach in IT departments, where engineers and developers are called upon to solve problems and resolve particularly difficult incidents, but they hand over to the operations staff the know-how required to resolve similar incidents, should they recur. With the constant changes in technology and the increasing complexity of systems, there will always be cases for knowledge workers to resolve. But, one objective of continual improvement is to make such cases easier to resolve in the future, handling them in a more routine, process-oriented way. This principle is well known to IT service management practitioners, who create models for handling known types of changes, incidents, events, configurations, etc. The routine, low risk change may be handled as a standard change. Continual improvement corresponds to moving along the scale from the innovative to the commonplace. At any moment in the history of handling a certain type of knowledge work in an organization, we should always be trying to address a certain percentage of those cases in a more routine way, whereas the remaining cases represent the core of purer knowledge work. (The concept of cases developing into standard process handling was already developed by Rob England.)
[…] have discussed elsewhere in these columns the relationship between process-oriented work and adaptive case management. This framework will help us to refine the understanding of how incidents may best be handled. […]