Pre-industrial risk assessment
Risk assessment remains a highly manual activity in all organizations I have ever seen. Some organizations have a structured approach to assessing, and then managing, risk. Others work largely with a seat of the pants approach. But in both cases, the activity of identifying risks and their magnitude and the creation and maintenance of a risk register is very frequently a work fashioned by hand, just as objects used to be crafted in the pre-industrial era.
Why is manual risk assessment an issue?
There are many reasons why this work by artisans is problematic. It is extremely labor intensive, meaning that it is slow and expensive. The approach is often not reproducible, casting doubt on the validity of the results. The number of different possible threats and the vulnerabilities to those threats of a very large number of classes of components is so large, that the resulting risk register tends to be composed of commonly known risks and risks that are relatively easy to identify and assess. But the objective is to identify the greatest risks, not the ones that are easily identifiable. Assessing risk depends on a very large number of factors that ought to be treated in a coherent and consistent way, from threat to threat and from asset to asset. In addition, the sheer volume of risks makes it unlikely that a manual approach will identify more than a small fraction of them. As a consequence of all these issues, the controls put in place are not necessarily the most effective means for reducing the global impact of risk. All of these issues are compounded when risk assessment becomes a high volume, time sensitive activity, such as in the context of change management.
How can automation help?
Risk assessment is a classic example of an activity that would benefit enormously from automation. Before we consider what form that automation might take, note that the risk management software currently available is not at all concerned with the sort of automation of which I speak. These tools tend to focus on such functions as:
- the maintenance of a risk register
- the tracking of controls and residual risk
- the reporting of compliance with company policies and with industry or regulatory constraints
- the automation of workflow
- the provision of risk-related databases
- auditing
- automated vulnerability testing
- the historical analysis of data in an effort to predict future levels of risk and support decision making, using Bayesian and other statistical approaches, as if what’s past is prologue
- the management of insurance claims.
Limits to existing automation tools
From the perspective of automation, the existing tools that I find the most interesting are those used to automate vulnerability testing. While these tools can be very interesting, they have certain limits:
- they can only test vulnerability to known threats
- they cannot know the value of the assets whose vulnerability is tested, therefore they cannot really prioritize risks; they can only prioritize vulnerabilities (for whatever that is worth).
Factors determining risk
In order to describe the automation of risk assessment, let us first summarize the factors determining risk. Once a set of controls are in place, the residual risk may be measured by:
- the value of the assets that are at risk
- the nature of the threats that might alter the value of those assets
- the probability that a threat will be realized
- the vulnerability of assets to realized threats.
On the basis of these factors, a risk level may be determined for each combination of asset, threat and vulnerability. These risks are commonly described as qualitative or quantitative. A qualitative analysis is simply one for which the skills or data is lacking to make a quantitative analysis, or for which it is assumed that the cost of acquiring those skills or data would exceed to probably destruction of value due to the realization of the risk. Automation should help to reduce the proportion of risks that can be assessed in only a qualitative way. Be that as it may, in all cases some algorithm is used to calculate a set of risk values. What sort of automation is possible?
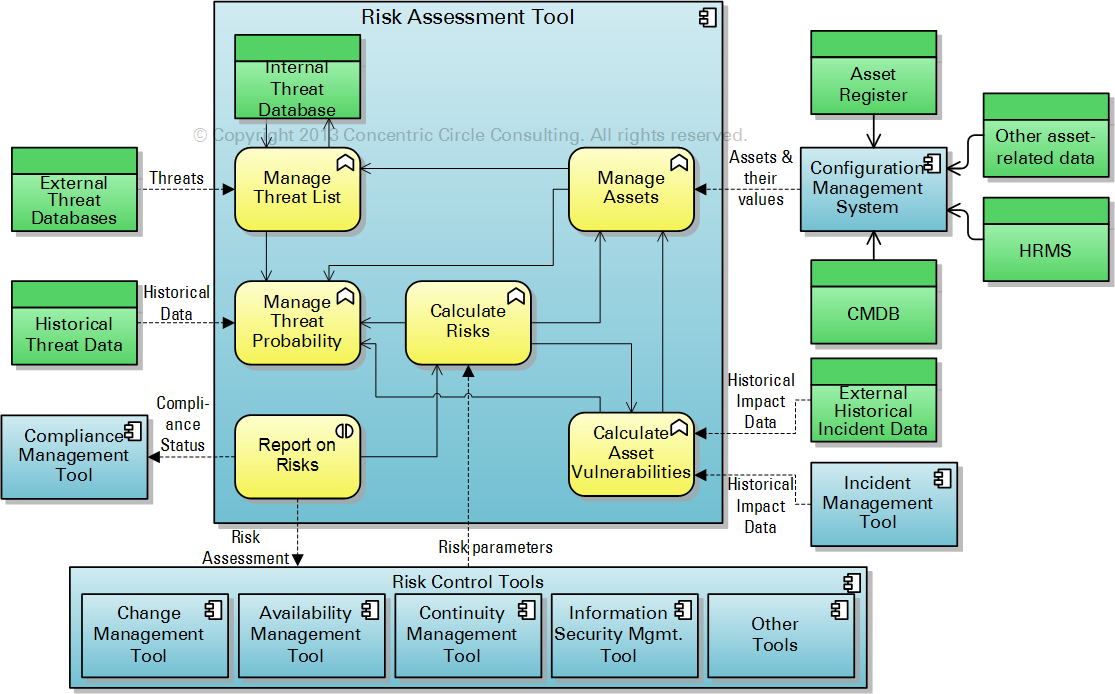
Fig. 1: Illustration of the tool architecture discussed in the text
What can be automated?
Asset Values
A list of assets and their respective values may be determined from an asset register. A simple asset register, however, is utterly inadequate to the needs of automation. There are three reasons for this:
- the granularity of an asset register is often inappropriate for the measurement of the risks to individual components. For example, an asset register might list a license for 100 users of an application. We are interested, instead, in the risks of specific instances of that application installed on certain platforms. The inverse issue exists, too. We might know the price of every server in use, but certain threats concern the servers in a cluster, rather than the servers individually.
- many threats concern the systematic relationships among assets, rather than the individual assets. We cited above the example of a server cluster; many threats only concern the vulnerabilities that exist in systems, rather than in low level components of those systems.
- many assets are generally not recorded in an asset register. Examples would include the people who operate, administer and use IT services; or the intangible assets, such as reputation, goodwill or even IT services themselves.
An automated risk assessment system requires access to up to date asset information, including intangible assets, described by the architecture of the systems, such as we ought to have in a CMDB.
The Nature of Threats
Vast of array of possible threats has triggered a cottage industry of creating lists or databases of these threats. Certain risk management tools include such a database as a means for delivering a packaged solution to certain risk management issues. A simple list of threats has a certain appeal to those working with a manual, check-list approach to risk assessment. For those who wish to automate risk assessment, two additional aspects of threat lists should be included:
- an open interface to external lists of threats
- a means for defining the potential scope of each threat
It is generally assumed that the bad guys are always one step ahead of the good guys in terms of their creativity in finding new ways of attacking the assets of others. This constant one-upsmanship requires that our list of known threats be regularly updated. Furthermore, individual lists or databases of threats are virtually always limited in their scopes. No single list attempts to cover all the threats that might attack all the assets we might have. Therefore, the more an automated system can open itself to external lists of threats and regularly adapt itself to the constantly changing list of threats, the more effective it is likely to be.
An example of such a system would be the data provided by many organizations offering anti-virus solutions. For each virus—that is to say, for each threat—data is collected and analyzed concerning how frequently it is detected, where it is detected, what types of systems are vulnerable to each virus, and so forth. The analogy with a virus database has its limits, however. An automated anti-virus tool has certain severe constraints that do not apply to a generic risk assessment tool. In order to work, an anti-virus tools must offer real-time protection that does not adversely impact performance levels. These two constraints have severely limited the tool makers ability to find a holy grail of anti-virus protection. The strategies of identifying suspect behavior and identifying known threats are always less effective for protecting against new threats. A risk assessment tool is not necessarily constrained by these same performance issues, thereby allowing for the use of different algorithms for detecting threats.
The effectiveness and performance of an automated risk assessment tool is nonetheless highly dependent on understanding the potential scope of each threat. By scope, I refer to the types of assets that any single threat might attack. It is useless to put a lot of effort into analyzing the risk of a threat that simply cannot attack a certain type of asset, given the very large number of assets and threats that abound.
Defining a scope for each threat implies some form of ontology of assets. Remember that we have defined “asset” in a very wide sense, including not only the physical objects in which we invest capital, but also their sub-systems and super-systems, as well as intangibles, such as processes, brands, good-will, etc. This ontology should be implemented in the configuration management system to which we referred in the discussion of asset values.
Probability of the realization of threats
Each of the threats identified in the lists mentioned in the previous section may be linked to one or more assets. Each of those links has an associated probability of the threat being realized. For example, an organization might have two data centers, each of which is internally identical. A data center is, in principle, threatened by flood. However, if one of those data centers is located on a river bank and the other data center is located on a high plateau in desert, the probability of the first data center being flooded is certainly higher than for the second data center.
There are many methods for assessing the probability of any single threat attacking any single asset. These methods are highly developed by insurance companies, for example, insofar as their ability to earn money depends in large part on these assessments. I am not advocating any single method for assessing probability. However, it is likely that any effective methods will combine evaluations based on historical data (where available) with logical extrapolations (where no historical data is available) and with evaluations that are intended to account for discontinuous events—the so-called “black swan” events. To continue with the flood example, it is common for geographical regions to be assessed in terms of the 100 year high water mark for flooding. If we have such historical data available, they should certainly be used to assess the probability of a data center being flooded. However, all such evaluations are based on a set of assumptions which may invalidate any predictions based on past events. For example, the recent flooding of lower Manhattan would not have been predicted by such an analysis. We make assumptions about the possible ranges of parameters, such as average temperature, and often fail to take into account that slight variations outside of those ranges may result in radically different results, going from a highly predictable and stable system to a largely random and unstable system.
Asset vulnerability
I cited above the example of two identical data centers, excepting their physical locations. However, assets are generally not identical. Two hard disks of the same model, subjected to the same loads over the same period, are not likely to fail at the same time. In other words, vulnerability is determined by design factors, by the slight (or great) variances from specification that exist in building of assets and by the operational factors to which the asset is subjected.
Among the operational factors, we should include the creation and the maintenance of controls designed to reduce the vulnerability of an asset to one or more threats. We might, for example, build a dyke around the riverfront data center, thereby reducing its vulnerability to flooding.
In the context of risk assessment tools, there are two approaches to assessing the impact of vulnerability. One approach is to simply assess the current state of affairs, including any controls that may already be in place. The other approach is to allow for simulations and what-if analyses, such as “how would overall risk be changed if we were to build a dyke around the data center?”
In order to be used in an automated risk assessment system, vulnerability must be measured in the same units as risk. A relative vulnerability assessment, such as “building a dyke will make the data center less vulnerable to flooding” will simply not do. As for risk, we need to state vulnerability in terms of the likelihood or probability of a given threat reducing the value of the asset by a given amount. For example, “the probability that a tsunami of 20 meters will cause a total loss of the data center with a 3 meter dyke situated next to the ocean is 90%,” “the probability that a storm surge of 4 meters will cause $1 million of damage to a data center situated near the ocean is 50%”, and so forth. The possibility for automating risk assessment is limited to cases where we can make or calculate such evaluations of vulnerability.
There are several strategies for handling the extreme complexity of evaluating vulnerability. If we really cannot judge by how much a given threat will damage a given asset, we can assume that the full value of the asset will be lost. The result will be an exaggerated assessment of risk. Perhaps this exaggeration could be mitigated by calibrating the final assessments, as long as we make the same error in evaluating vulnerability for all assets and threats. We may also work on calibrating our own estimates, rather than giving up entirely.
Another strategy is to use historical data to determine how similar incidents in the past affected asset value. The same possible errors discussed in evaluating the probability of a threat occurring should be taken account when extrapolating from the historical record.
A third strategy involves modeling the asset-threat relationship. Modeling has the advantage of abstracting and simplifying a potentially infinite number of sizes of threats. Let us take the example of a data center surrounded by a dyke of a certain height threatened by floods of different heights. A mathematical or statistical model may allow use to take into account complete ranges of dyke height and flood height and the resultant probable impact on data center value.
The calculation of risk
Once we have described the assets, their values and how they interact in systems; the various threats to each of those assets; probability that any given threat might attack any given asset; and the vulnerability of that asset to that threat, we need to calculate the risk.
Many risk calculation methods, adopted because of their simplicity, are examples of what I call “voodoo” assessments. I have already talked about voodoo assessments in my book, IT Tools for the Business when the Business is IT, where I refer to the strange habit of prioritizing tools on a short list using methods that have no relationship whatsoever to tool value. A voodoo assessment of risk is similar, in that it is based on completely arbitrary and unscalable magic numbers. This is typical of the so-called “qualitative” risk assessment, where vulnerability or threat probability is evaluated as “high”, “medium” or “low” or some similar scale. The problem arises when “high”, “medium” and “low” are assigned numeric values and then these values are multiplied by each other, or added to each other, or some other algorithm, in order to generate a risk value. Such values are largely meaningless and are of no use in an automated system. Sticking pins in voodoo dolls is just as likely to give useable results.
This is not the place to discuss in detail the methods by which risk should be calculated. Suffice it to recall that risk is a measurement of uncertainty. Therefore, risk should be expressed in terms similar to the following: “There is an 80% risk that threat A will reduce the value of asset B by an amount between X and Y.” The purpose of expressing risk in such terms is to enable decisions about the controls that might need to be put in place to make that risk more acceptable. For an extended discussion of methods that might be applied to the metrics of risk, I refer the reader to Douglas Hubbard’s How to Measure Anything and The Failure of Risk Management.
Using automated risk assessment
There are various use cases for an automated risk assessment tool.
Maintain a risk register
The standard output of the risk assessment discipline is a risk register which is, at its core, a list of prioritized risks. An automated risk assessment tool will create and maintain that register. It will differ from a manually maintained register in terms of its completeness, accuracy and the effort required to maintain it. The register is likely to be many orders of magnitude larger than a manually maintained register, for the simple fact that manual work could not possibly create and maintain as many data as an automated tool.
Documenting regulatory compliance
The sheer amount of effort required to manage risk and document that management is itself a risk to the ability to comply with regulations. Of course, a risk assessment tool will not, by itself, document the existence and the effectiveness of any controls in place. It will, however, provide a more complete risk register and provide better justification for the needs for controls or, conversely, the lack of need for certain controls. As long as the automated risk assessment tool is using state of the art data sources for threats; is accessing a well maintained configuration management system; and uses industry accepted algorithms for calculating risks, auditors cannot but accept the well documented conclusions of the need for controls. The descriptions of those controls and their links to the risks themselves need to be documented as part of whatever risk management tool is used in parallel with the risk assessment tool. The risk management tool should build upon and update the same risk register maintained by the risk assessment tool. Needless to say, both risk assessment and risk management may be integrated into the same tool.
Assess the risk of a change
An automated tool should have an interface with a change management tool. The change management tool would send data about the proposed change, including such information as the CIs to be changed; the context in which the changes are to be made; whether the change involves new, modified or deleted components; when the change is planned (although the final planning is apt to come after the risk assessment); who is to perform the change, the expected value of the change, and so forth. On the basis of these parameters and the other information known to the risk assessment tool, such as the infrastructure architecture, the threats to the components and systems concerned, and the vulnerabilities of the components concerned, the risk assessment tool would return a risk statement in the form described above. The change management actors, such as the CAB members, would then decide if the risk is acceptable or if additional controls are required before approving the change for implementation.
Define a continuity strategy for a service
A business impact analysis performed in the context of service continuity management identifies the assets at risk (the services and related assets) and it makes an assumption about the vulnerability of the service to a theoretical threat. That assumption is that there will be a catastrophic loss of service. Its value will be reduced to 0. Defining strategies for restoring that service in case of catastrophic loss depend on both the BIA itself, as well as an assessment of the probability of that catastrophe. This latter information may be provided by the risk assessment tool.
Design a system architecture
The availability management discipline should play a significant role in the design of any IT system. At the very least, it should be aware of the availability requirements for the services delivered with that system; support the design of the system to meet those requirements and to conform with any architectural policies in place; and ensure that the means are available for measuring the availability of the services using the system as well as the components out of which it is built. A more advanced availability management will also support the building in to the system of reliability, maintainability and serviceability.
The appropriate design of a system requires finding the right balance between the design features described above and the cost of building, maintaining and operating that system. A critical factor in finding the right balance is the assessment of the risks to achieving a given availability level for a given architecture. The risk assessment tool can support the simulations of different architectures as a means for balancing cost against availability. It should be noted that such tools do exist, although they tend to be limited in scope to specific levels in the technology stack, such as for the design of a data network.
Risk assessment is a Big Data application
Risk assessment in the context of IT service management is one of those areas where technology is playing catch-up to process definition. We have at our disposal a large variety of working methods and formal processes designed to assess and manage IT risk. And yet, the technology used to support those activities is still in the dark ages for many organizations.
It does not take a data scientist to realize that the effective assessment of risk involves handling quantities of data on the scale of what we call today “Big Data”. Our hope is that the techniques now in use and being developed for getting meaning out of very large quantities of data may be applied to the assessment of risk, thereby dragging us away from the primitive, seat of the pants approach to risk assessment that so many organizations have today.
would you be able to share a few free automated risk assessment tool which you have tried using?
As a matter of policy we do not refer to specific products, free or otherwise. A large number of sites are in the business of making such lists, such as capterra.com. You can also find tools, open source and free, on sites such as github.com