My experience with process architecture principles
Over the years, my advice to clients seeking to improve how they work has been underpinned by a set of implicit process architecture principles. I would like to share them here and explain my reasoning behind them.
How I am using the term “process”
Before going into those details, I need to make clear what I mean by the term “process”. An explanation is necessary only because most of the major frameworks in the area of service management have used the term in an idiosyncratic way. For me, a process is simply a structured way of doing work. I have talked about the degree to which that structure needs to be defined in a separate article, The minimum viable process. In short, when the work being done has a variety of different purposes and outputs, delivered to different types of customers, responding to different triggers and being performed by different workflows, then I do not consider that we are dealing with a single process. Rather, this work is being done by a variety of different processes, even if they concern closely related entities, roles and outputs.
When a framework such as ITIL® says that something like service level management or capacity management are processes, it is really referring to what an enterprise architect might call domains. And this, in spite of ITIL’s own definition of process in its glossary. In more generic terms, they might be described as disciplines, not processes. The work done in the domain or discipline of service level management, for example, is organized into multiple processes. There is, for example, a process to negotiate and agree on service levels. Another process reviews performance against those services levels and defines improvement steps. And yet another process produces service reports, and so forth. So, service level management is not a single process. It is a domain or a discipline within which a set of related processes are performed. Be that as it may, the damage due to ambiguous use of the term “process” is done and we need to live with it.1
Without further ado, let me explain some of the process architecture principles I use.
One output, one process
One of the components of the minimum viable process, as I have described it (see the link above), is its output. A process needs to create some output if it is to do any useful work. I would propose that any given output should be created by only one process. You should not have two processes creating the same output.
That might seem self-evident to some, but many organizations do exactly the opposite, at least in certain cases. The most common example, in my experience, is to use two different processes to resolve incidents. What happens, in practice, is that they try to resolve the incident with an incident management process. If that does not work so well, they resort to what they call a problem management process. Now, in such cases there really are two different processes, so it is not a matter or terminology. But there is also a radical misunderstanding of the respective purposes of problem and of incident management.
When you have two (or more) processes trying to achieve the same thing, you significantly add to operational and maintenance overhead. There will inevitably be a decision to make, and a resulting tension and waste of effort and time, as to which process to use. Confusion in the minds of the actors is the inevitable result. And reporting becomes that much the less meaningful. For, if you create a report about how long it takes to resolve an incident, it should include in its scope all incidents. And yet, most reporting tools are based on the process-related records (as is necessary). Can you imagine a report about problem management in which it is stated, “Oh, and by the way, some of those problems were really incidents—we weren’t resolving problems at all in those cases.” And in parallel, the report about incidents says, “This report only concerns the incidents that are easy to resolve. For the hard ones, see the report on problem management.” I, for one, would have reduced confidence in the people generating such reports.
And yet, one could readily imagine that a single enterprise might have multiple processes for doing the same work. The most common reason for this is that different business units use different processes, often due to historical reasons, to different levels of maturity or to different levels of access to the required resources. Therefore, when I advise that an output be created by only a single process, I am referring a scope limited to the organizational unit using those processes. One company, for example, has a pharmaceuticals business unit and a diagnostics equipment business unit. They both have a change management process creating the same output, but the processes are different. This is perfectly fine, and perhaps even desirable. The pharma unit never uses the diagnostics unit process, nor does the diagnostics unit ever use the pharma process. However, it would be problematic if one of the units did have two or more different processes to deliver the same output. Consequently, we may reword the principle to say that a given team, when faced with the need to create a certain output, should be using only process to create it.
One activity, one process
When we look at all the different types of work we do in an organization, the question inevitably arises of how to divide up that work into separate processes. I suggest that a given activity should be part of only a single process. This principle is much less self-evident than the preceding principle. There are two underlying issues.
Activity homonymy
In some cases two activities have the same name, but they are really doing different things. Many management process have a recording or a classification activity. While the abbreviated activity name is shared among multiple processes, and even some of the methods for performing the activity might be shared, they are acting on different objects. You would not, for example, classify a problem or a configuration item when performing the classification activity in incident management. But more importantly, you should not want to do so. In the cases of activity homonymy, my principle is being respected. The second underlying issue is just the opposite, however.
Activity polyphony
In this case, the same activity is being performed in two or more different processes, acting on the same object, and typically using similar methods. The most common example of this is the activity of assessing or approving a change to a configuration item. Many organizations do this in the context of a process they call “Change Management” or “IT Change Management”. But they also do this in a process they call “Project Portfolio Management” or “Project Management”. In addition, they do it implicitly in the context of making strategic decisions, product design, reorganizations and policy changes, even if no explicit name is given to those processes.
I have worked with one company that can schedule changes in (at least) three different ways: as part of project planning, as part of release planning and as part of change management. You can imagine the difficulties of meeting the goal of optimized scheduling, wherein there are no conflicts and dependencies are respected, when you try to achieve that in three separate ways.
Activity polyphony tends to lead to a proliferation of supporting tools, all doing more or less the same thing; wastefulness due to incoherent information and work done to correlate it; and great difficulty in applying simple principles across the board. Taking the above example, imagine that the planned dates for some change implementations are found in a project portfolio management tool or, even worse, in a series of separate project plans; other dates are defined in a spreadsheet containing a release calendar; and yet other changes in a service management tool or a change calendar on a web page. Sure, there are means to coordinate these dates and update all three tools as required. From a lean perspective, that is pure waste. So why should you have to do it at all?
Now, let’s suppose we want to apply a single principle for prioritizing all changes. In my experience, every team or every business unit will tend to interpret and to apply principles in their own ways, making different assumptions about the meanings of each priority. As a result, it is much more difficult for top management to implement the changes it might want, than if there were a single place where the corresponding activity is performed. And the common response to such a wasteful situation is to reinforce governance, itself a form of waste.
This principle highlights the fact that a process architecture cannot be defined in isolation from other architectures, such as the data architecture or the application architecture. In the service management realm, I have treated the relationship of process architecture to application architecture and to the managed entities in considerable detail in my book, IT Tools for the Business when the Business is IT. In the example provided above for change management, we see that the definition of the scope of the configuration item entity is directly related to the issue of how many different activities assess or authorize changes to them. However, to analyze the issue in this way begs the question. If you are keeping an item’s configuration under control via an activity that assesses or approves changes to it, that entity is, by definition, a configuration item. The mere fact that you may have an incoherence in the definitions of the scope of change control and the scope of configuration items does not make this any less true.
The fat lady has sung, so its over
A corollary to the one output, one process principle is that a process should terminate when it delivers the output that corresponds to the process’ purpose. This principle has three major implications.
An end to “end-to-end” processes
I have frequently seen cases where a “process” is defined as the set of activities used to manage a object throughout its life-cycle. For example, a release management process has been defined to cover the release and deployment of a single release onto each of the various environments used—development, QA, UAT, staging, production, etc. One “process” is meant to cover everything from end to end. What I propose, instead, is that you really have five, related iterations of the process, one iteration for each environment. A similar example may be found in the change management process for certain organizations. They map the process to the entire life of the change, from its initial proposal until its final implementation. This span generally includes two complete iterations of assessment, approval and planning—once for the initial proposal and once for the implementation in production. In the case of certain anal retentive organizations, there are even more approvals required. Once again, I would prefer there to be two (or more) related instances of the change management process. The major reason for respecting this principle may be found in the following principle, concerning non-embedding of processes.
A second issue with so-called “end-to-end” processes is the extreme complexity and the high overhead required. One of my clients had defined no fewer than 89 different “end to end” processes for managing the end users’ workplaces. But each “process” included activities from configuration management, from change management, from incident management, and so forth. Thus, a single change in the way a configuration item might need to be managed required an update to more than 30 documents. In any case, who could be expected to learn and to use religiously all 89 processes? Creating so many processes was an exercise in monomania by an omphaloskeptic. I was able to reduce that to six very short processes, linked in various ways.
Does this mean that there is no value in understanding how an organization works, from “end” to “end”? That is not what I wish to imply. The end to end perspective is especially important during this transitional phase during which organizations are becoming more lean and agile. This broad perspective allows us to identify, for example, situations where a lean approach is applied to only a part of the end to end value chain and the constraints on that approach, due to its partial implementation. Such neologisms as “water-scrum-fall”¹ have been created to describe such situations.
Do not embed processes
In many cases, organizations define processes such that in the middle of one process, another process is triggered and the first process is suspended until the second process is terminated. This is what I mean by embedding processes. Note that this case is completely different from the case where one process creates output that is used in another process, but there is no synchronization of the processes, no need to wait for a return from the second to finish the first.
There are many cases of this phenomenon. The worst case is in a change management process, such as ITIL has defined it. According to that process, there is a gap between the scheduling of the change and the closing of the change record. This gap depends on whatever process might be used to perform the change itself, such as release management. And a second example is in release management, according to that same framework, which is not only interrupted a number of times by change management, but also depends on such processes as test management.
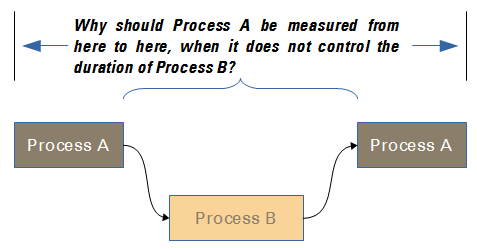
Respect of the principle of non-embedding is critical to the management of the process in a lean way. It should be obvious that any management approach shall want to keep the average lead time for a process to a minimum. How are we supposed to measure that lead time if, in fact, part of the process duration is dependent on an entirely separate process, with its own manager and its own resources, its own lead times and its own forms of wastefulness?
The typical “save-the-paradigm”2 type answer to this issue would be to stop measuring process lead time from the status “new” until the status “closed”. Instead, you would have to measure only until some intermediate status, such as “resolved” or “approved”. In this unsatisfactory approach you end up doing work at the tail end of the process that doesn’t get measured at all. That is, unless you have multiple separate measurements, creating a complex, byzantine measurement system unable to provide simple answers to simple questions. I don’t believe you should have to do this. My recommendation would be to define the process so that it is measurable from end to end, that none of the work done in between depend on embedded processes, and that the process’ end be simultaneous with the delivery of the principal process output.
Determine when a process ends by looking at the purpose
I have often asked people with significant roles in a service management process what the purpose of their process might be. It is perhaps shocking that many of them, often with formal certifications and qualifications in the domain, have the greatest difficulty articulating the process purpose.
Some of the fault is due to the standard frameworks in the domain, which have missed the opportunity to say something useful when supplying a process’ purpose. For example, what are we to make of the statement that problem management is “…the process responsible for managing the lifecycle of all problems”? Well, we should be glad that that issue was cleared up.
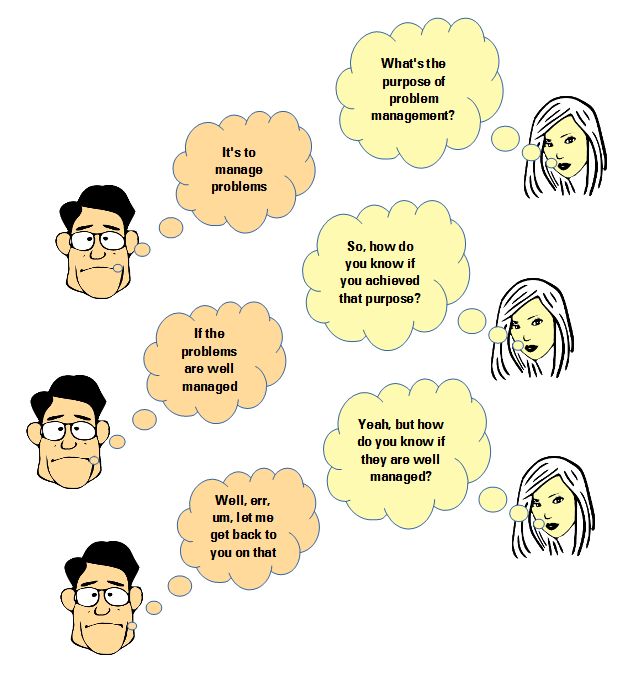
If we know the purpose of a process and if we know when the output that fulfills that purpose is delivered, then we should be able to say when the process has finished. But what about those processes that continue to perform work even after the purpose has been fulfilled? There are three possibilities for this work: 1) it is useless and should be stopped; 2) it is valuable only because work that should have been done earlier was not done, or not done at the required level of quality—in other words, it is a form of waste; 3) it is valuable work that should be continued to be performed—but not as part of that process!
Fortunately, I have seen few examples of case 1, so I will not pursue that issue. Case 2 would include such examples as correcting erroneous information in a record, as is often done in incident management, where the quality of the information recorded is often poor. By institutionalizing this sort of activity, rather than understanding and correcting the causes of the problem, you make this form of waste a permanent feature of the process.
Another example would be the separation of performing a service act for a customer and getting confirmation from that customer that the result is OK. Typically, we are talking about fulfilling service requests and performing customer support. In my view, the performance of the service act should not be considered as finished until that confirmation is given. It should not be treated as a separate process activity. What might seem to be a minor distinction is actually at the source of a huge amount of confusion, customer dissatisfaction and waste.3 There is a huge increase in effort and in dissatisfaction if a customer is obliged to come back after work is done only to say, “That’s not what I asked for” or “It’s still not fixed.” When you set the status of work to resolved, that should not mean that the work has been performed. It should mean that the customer’s need has been fulfilled. And you should never create a separate ticket, instead of reopening a ticket. Creating a new ticket simply serves to hide the gross inefficiencies of the process, making it all the more difficult to identify the problems and make improvements. I fully recognize, however, that work in a technical domain, such as IT, is often done at a distance and without customer interaction (this is especially the case for internal IT support). It is not always practical to get immediate feedback from the customer that the result is satisfactory. Be aware, though, of the resulting potential for a high degree of waste.
A typical example of case 3 would be a process feedback and improvement activity. This should very definitively be performed, but it should not be part of the process itself. Standard frameworks often include at the end of processes such activities as “post-implementation reviews” or “major xxx reviews.” While putting these activities into the relevant processes themselves, there is undoubtedly a short feedback loop. I set aside for the moment the fact that such reviews are often little more than closing the barn door after the horse has escaped. Be that as it may, from a lean perspective such activities are not value-adding to the event handled by the process instance. At best, they might add value in future process instances. In addition, reacting to a single event, without assessing the longer term history of the process, is a typical human bias, that can easily lead to what Deming call “tampering“. Therefore, perform them by all means, but as part of a separate process improvement process that seeks to improve the process based on more than just one event5.
Conclusion
By applying these principles, an organization can have a process architecture that:
- has a simple structure
- is easy to maintain
- is easy to measure
- is easy to manage
- helps eliminate many forms of waste
If you are interested in achieving these goals, I would invite you to consider using these principles as guidelines for the definition and the evolutionary improvement of your processes. I emphasize the word guidelines, rather than hard and fast rules, because there are inevitably cases where it might be desirable not to follow them. But such cases are most likely exceptions that prove the rule, and the rule comes out strengthened by that experience.
![]()
1I am far from the first to make this remark. See, for example, the first edition of Charles Betz’ Architecture and Patterns for IT Service Management, Resource Planning, and Governance: Making Shoes for the Cobbler’s Children. I do not mean to imply, however, that Betz shares my understanding that we are often talking of domains or disciplines, rather than processes.
2See Dave West, et. al., Water-Scrum-Fall Is The Reality Of Agile For Most Organizations Today. For those without access behind that paywall, see also Jack Vaughan, Forrester’s David West on Lean applications, Agile and SOA
3See Thomas S. Kuhn, The Structure of Scientific Revolutions, for this reference. The idea is that scientists are loath to abandon the theories underpinning their work, so they instead devise complicated explanations for the issues detected.
4This issue is at the heart of much of the message of John Seddon. See Freedom from Command & Control. Rethinking Management for Lean Service.
5For example, in the Kanban approach to managing the flow of work, the daily stand-up meetings and the monthly operational review play key roles in process improvement, but are external to the flow of the value stream itself.

Thks for the article. Now is time to think about it. About “embeding processes”, I can’t be more agree woth you, the case with change, release, testing, evaluation and so for, is a good example of complexity.
Greetings from Mexico. DMT
Your message advocates definition and discipline. Unfortunately, too few ITSM providers are committed to being so methodical, paced and measured. I believe the principles you advocate would support achieving SLAs in profitable ways but I have not seen this kind of leadership and commitment to constancy.
You are probably right, John, which is why I thought it was worth writing about. I frequently encounter practitioners with only a fuzzy notion of what their processes are supposed to be doing, why they are doing what they are doing and how to measure if they are truly successful. We should be able to bring the same clarity to service management processes as to any other type of work, be it how to manufacture a widget, post an accounting transaction or buy paper for your printers. I am convinced that the service providers that fail to achieve even these very basic characteristics of the work they do will simply go out of business, sooner or later.
Good article. I agree that incident and problem management are actually the same process. I have been thinking about what are the real support processes and this is my list:
* request or order management to fulfill orders.
* support management to solve customers’ problems
* fault management to solve technical problems
Risk management is also necessary but is it a process or a domain?
I think that the incident-problem management model is causing a lot of unnecessary work for many IT organizations and the practice of entering events as incidents in the same workflow as customer’s problems just makes it worse.
Thanks for these remarks, Aale. John Seddon (e.g., in Freedom from Command and Control), has made very strong arguments for distinguishing request management from support management (as you describe them). I fully agree with that perspective. I understand the reasoning behind separating support management from fault management. This is certainly a good approach when the supplier is producing tangible goods. But when the supplier is producing services, the two can be so tightly entangled that having two separate processes might result in a lot of redundancy and inefficiency.
As for risk, managing it via a specific process is rather like saying the quality is the responsibility of quality assurance. Ha! Risk, like quality, is an aspect of everything we do and all economic actors must understand it and build its management into their own activities.
As for incidents and problems, this is probably not the right place to get into a long discussion. But I think it all resolves down to the question, “Can you resolve an incident without understanding its cause?” In many (probably all) of the organizations with which I have worked, the systems they create are so complex that many incidents cannot be resolved effectively without some degree of cause analysis. Which leads to a certain level of confusion and redundancy when you tell people to manage problems separately from incidents. But what if an organization did a really good job of designing systems and, like in any other domain, there was extensive FMEA analysis in the design phase and the resulting systems were designed to be easily maintainable? In such a case, it would be much easier to resolve incidents without investigating the causes. And therefore incidents would be resolved much more quickly and reliably (and there would probably be fewer incidents, for that matter). In such a case, the distinction between problem management and continual improvement could fade away (they are really the same thing, in the end).
Thanks Robert. I know that sometimes the support and fault are quite close. The argument for separating faults and customer problems is that they are also quite different. A customer problem is about one specific customer and it can be closed when the customer is happy (or former customer). A fault is related to the service infrastructure and is not necessarily related to any single customer. One fault may affect many customers but in different ways. Of course customer problems and faults can come together and then there is not much benefit of separating them.
I’m not sure of CSI is the right way of handling difficult problems. All organizations tend to have unsolvable problems and risk management is the right way of handling those. ISO 31000 describes it pretty well.