One of the main benefits of a lean/kanban approach to IT is the simplification of processes expressed in the value stream of each team. But IT teams are sometimes indoctrinated with process frameworks coming from approaches such as COBIT® or ITIL®. They may be at a loss to understand how a single value stream can represent all the work they do. Unfortunately, the many examples of IT kanban boards we see are of little help. This is because they often are based on the needs of application development. In this article, I will propose a generic value stream for service management. Then I will examine how it applies not only to service management, but to the other typical IT activities.
Teams that are already using kanban to manage operational work are likely to have found their own solutions to defining value streams. For other teams, my purpose is not to prescribe any single value stream. Instead, I would like to demonstrate that a kanban board for non-application development is indeed feasible. At the same time, I hope to stimulate reflection on the subject. Every team should be responsible for defining and refining the value stream that makes the most sense for it.
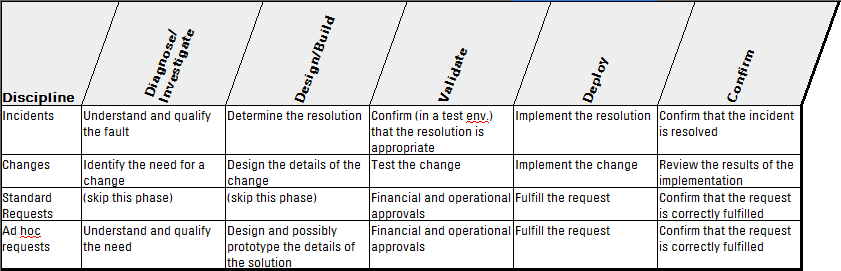
I propose the following phases: Diagnose/Investigate; Design/Build; Validate; Deploy; Confirm.
Value Stream Triggers
The value stream in a kanban board is most appropriate when dealing with work triggered asynchronously by a customer event. For work triggered by period or calendar, such as preventive maintenance, see the section below on Repetitive Tasks.
The specific events that trigger any work item are not part of the value stream. In principle, the triggering event is first handled by the customer for the work item, who places that item in the ready column of the team’s kanban board via the normal replenishment procedure. In a service context, the typical events are standard service requests, requests for changes to or additions to services and reports of incidents. Remember that such events could also be generated internally to the service provider. They could include, for example, the identification of problems and the various needs to manage the service system.
Skipped Phases in the Value Stream
Note that not all phases are obligatory for all work items. For example, the distinguishing characteristic of a standard request is the fact that the it has already been qualified and classified. It’s fulfillment method is already defined and approved.
How should kanban cards for such work items be handled? I suggest that the skipped phase (or phases) include a buffer in front of the following phase. In the case of standard requests, for example, the kanban card would be put directly into a buffer column following the the design/build column, after it is first put in the ready column. This allows for a) overall control of the work in progress; and b) creates a commitment point for the standard request work item. In other words, the team commits to the standard request only when it is ready to start its validation or its fulfillment.
Diagnose/Investigate
This phase includes any activity preliminary to the actual design or deployment of the solution. It corresponds to an Analyze phase in application development and could readily share that same name. This phase answers the question, “what are we really talking about?” or “what is the scope and nature of the work we need to do?”
Design/Build
This concerns the creation of the solution. For many activities, such as certain changes or incidents, the solution has already been designed so this phase might be skipped. For other activities, some new design work is required.
I have put design and build together in one phase in view of the fact that these activities are often one and the same, or because the same person is often performing both, or because these activities are often highly iterative. However, an organization with strictly separate roles for designing, as opposed to building, might wish to have two separate phases.
Validate
This phase includes any controls that might be required between the creation of the solution and its deployment. These controls might include testing, risk assessment, configuration documentation, change approval, and so forth.
From a lean perspective, the inclusion of this phase is a compromise between the purist’s approach to value streams and the “traditional” organization’s need to have management or user approval before deploying any solutions. Note, too, that many organizations do not treat such activities as testing as a separate phase, but perform any needed tests as part of the iterative, design/build activity. In such organizations, using methods such as continual deployment, it might be appropriate to speak of a design/build/test activity and eliminate a separate validation phase.
From a customer’s perspective, management approval, for example, may not be seen as a value-adding activity. However, industries such as pharmaceuticals may be required to demonstrate such controls. Therefore, there may be a need to include necessary, but non-value-adding, activities.
Be that as it may, validation activities may vary according to the category of work. For an incident or a problem, it might include testing the resolution in a test environment. For a change, it would include testing the change in a test environment. For standardized service requests, neither build nor testing activities would be expected. However, the validation phase might include financial or operational approvals.
Deploy
Deployment includes all activities required to introduce the solution into an environment where the customers may benefit from it. For incidents, this means repairing or reconfiguring the faulty components and restoring services. For problems, it might mean publishing workarounds or planned solutions. For releases or changes, it would be the implementation of the change or the new components in the target environment. For service requests, including access rights handling, it concerns to execution of the tasks required to fulfill the request.
Confirm
The confirmation phase has two essential aspects to it: risk management and communication. Operational tasks, especially when they are not handling standardized service requests, entail a certain degree of risk. These risks include:
- the risk of misdiagnosing work
- the risk of designing or building a solution that is not for fit use or for purpose
- the risk of incorrectly building a solution that was nevertheless adequately designed
- the risk of validating a solution using inappropriate methods or assumptions, such as performing tests in an environment that poorly reflects the production environment
- the risk of deploying a solution other than the one designed or tested
- the risk of failing to deploy a solution correctly
There are certainly many other risks. It is therefore of interest to confirm, based on experience in a production environment, that the work has been done correctly and is of value to the customers.
Once again, from a purist’s point of view, confirmation may not always be viewed as a value-adding activity. It could be included as part of the Deploy phase of the value stream.
For incidents, users may confirm that services have been correctly restored. For problems, users or support personnel may confirm that solutions and workarounds are indeed effective. For changes and releases, confirmation may include smoke tests, post-implementation reviews and longer term evaluations of the value of the change. For service requests, confirmation could be a simple acknowledgement that the request has been correctly fulfilled.
Using Swim Lanes for the Value Stream
Some teams may find it useful to break down their operational activities into different swim lanes
An example of the use of swim lanes may be found in Fig. 2. In this example, the standard service requests have been put in a separate swim lane. The Diagnose/Investigate and Design/Build phases have been blocked off for standard service requests, insofar as these activities are not required.
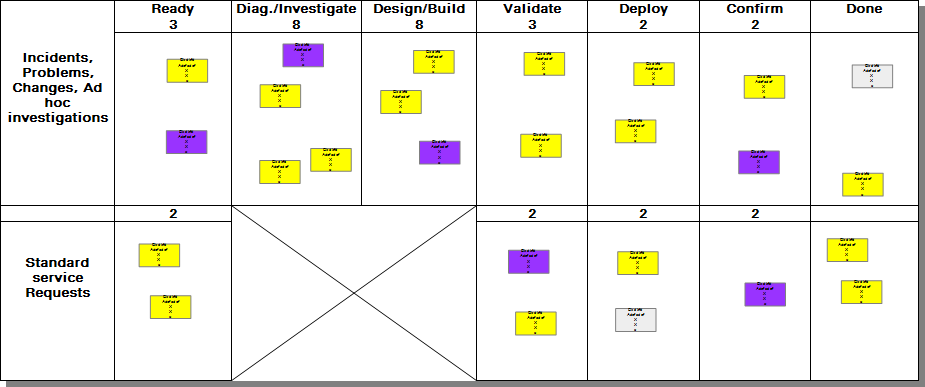
Note, too, that separate WIP limits have been set for the two swim lanes. Setting WIP limits by swim lane is not necessary. It is especially useful as a means for guaranteeing capacity for work items, such as incidents or intangible class work items.
Repetitive Tasks
Much of the work done in IT operations is of a controlling, repetitive nature. For example, an application administrator may be expected to review the application log for any curiosities, anomalies, or warnings. Data center administrators might be responsible for periodic cleaning activities or other types of preventive maintenance. DBAs or network administrators might review alerts or performance reports to ensure the good health of the systems for which they are responsible.
How do these activities fit into the value stream proposed here? I do not think they fit very well, although some may try to shoehorn them into some value stream.
A more useful approach to scheduling and controlling such tasks would be to use a separate board, with different types of cards, called by some a “TPM (Total Productive Maintenance) board” and by others a “Kamishibai board”. This board assumes that maintenance tasks are performed periodically—daily, weekly, monthly, etc. The board has a different section for each period. All the daily tasks are grouped together, the weekly tasks are grouped together, and so forth. For each task there is a corresponding card, usually with a red side and a green side. The name of the task, as well as other relevant information, is written on both sides.
At the start of the period, all the cards are turned so that the red side is displayed. When each task is completed, the person completing it turns the card so that the green side is displayed. Thus, the board implements the principle of visualization of work, making it easy for all stakeholders to see the status of that work.
As with kanban boards, the TPM or kamishibai board may be implemented as a physical board or in software. Physical boards typically have the cards hanging from hooks, making it easy to turn them over, with little wear on the cards or the board. Other boards have a slot for each task into which the corresponding card is placed.
Kamishibai boards may be used for any type of periodic, repetitive task, not just operational tasks. Another typical example of their use is for tracking periodic audits.
Other service management disciplines
The examples I have provided above are drawn especially from the service management disciplines that are most commonly used. How is the value stream applicable to other disciplines, such as availability management or service level management and so forth?
In fact, the work in all these disciplines either fall into the category of some work item that is triggered by a customer’s request or some repetitive, internal task. Please note a customer may be internal to the service provider organization, as well as external customers.
And what about application development?
I introduced this topic by referring to the fact that the most common examples of kanban boards for IT describe application development work, so they are not easily reusable by people performing operational tasks. Can we integrate development and operational tasks into a single kanban board?
Since the use of kanban boards for IT started first in the realm of application development, the occasional operational task handled by developers was either ignored on the boards, or was handled by creating a separate swim lane, with its own value stream, for these tasks. In this article, I have been looking at value streams from the other side of the coin. But, I think you will easily see that this same value stream can be used for application development.
This level of flexibility is important for cross-functional teams¹ that handle all aspects of individual services, be it the development of the underpinning applications, the design of the infrastructure, their testing and deployment, and all the activities required once the service is in production. It is both feasible and desirable to use such value stream models for structuring and managing the full span of work done by IT.
Other Models
There are models for doing IT work other than those implicit in such frameworks as COBIT and ITIL. Some of these other models, such as the OpenGroup’s IT4IT Reference Model or the ISM Method, represent significant simplifications relative to the aforementioned frameworks. However, from the perspective of a team of people organizing their daily work using a kanban board, these models cannot easily be used. They remain, above all, too complicated.
For example, the IT4IT model consists of a single value chain intended to cover all IT activities. That value chain consists of four value streams, each of which leverages a set of functional components. While this model might provide a vocabulary for describing the work done in IT, it does not describe the actual flow of that work. At the highest level, the model provides an architecture for relating value streams to the overall business of an IT organization. However, it stops short of describing the actual flow of work within any segment of its value chain, relying instead on reference to the various functions that might participate in the work. Whether you agree or not with the model itself and its prescriptive approach, this level of generality is appropriate, as each organization is apt to have value streams tailored to its own requirements.
John Seddon has proposed a generic service value stream: Understand what matters to the customer; Determine by what method the work would be done; Do the work; Review it against the original purpose. These phases map readily to the value stream I propose. Their emphasis on the flow of activities, however, is somewhat different. I would be very happy using Seddon’s terminology, though, especially in an organization with an extremely high degree of variability in the types of customer demand.
![]()
¹For a further discussion of the benefits of cross-functional teams, see my article Do we really need service desks?
The ISM Method too complicated? 🙂
I can easily teach that to children.
Actually you’re describing the basics of what has lead us to the ISM Method, 15 years ago. The missing link here is the understanding of the actual process areas.
This gets to a very basic level and is intricately looks at the build up areas. This is certainly a great job.
Hello! :-]
After reading twice this article, my mind come to two different ideas around it:
1) What was the need behind this proposal, is it a customer/business/organization one or a service provider one?
2) Is the fact that ITSM processes have activities on more than one phase in the service lifecycle, what make process execution difficult, the source of this proposal? If so, I ask myself: what about using the generic process model or the SIPOC? Isn’t enough to clarify the workflow?
These are my thoughts about this article. Thks for sharing it. Greetings.
Regarding the Other Models section, it is useful to point out that there are many other frameworks explicitly using a model ultimately derived from Porter’s concept of the value chain. For example, the European e-Competence Framework (http://www.ecompetences.eu/e-cf-overview/ ), speaks of Plan-Build-Run-Enable-Manage.
A value chain is certainly useful, I guess the ITIL Service Lifecycle is an attempt at a simple model for it.
I think this lends itself well to a case management approach. The plan/diagnose/investigate, triggered by a concept/event/need, can essentially involve that triage activity to push into the next phase.
I would agree that ITIL’s so-called service life cycle is not a life cycle at all. It more closely approximates a value chain, although the so-called CSI “phase” is neither a life cycle phase nor an activity in a value chain. At most, it represents activities that serve to change or tune the value chain.
However, I do think we need to distinguish between value chains and value streams, but that is for another time.
I agree the an adaptive case-based approach to management is easily integrated into this concept, though, as I think I have argued in a previous posting here.
I would agree that ITIL’s so-called service life cycle is not a life cycle at all. It more closely approximates a value chain, although the so-called CSI “phase” is neither a life cycle phase nor an activity in a value chain. At most, it represents activities that serve to change or tune the value chain.
However, I do think we need to distinguish between value chains and value streams, but that is for another time.
I agree the an adaptive case-based approach to management is easily integrated into this concept, especially if you recognize the importance of being able to skip phases.
An interesting version of the various phases of an IT project and that contained in the Swiss method for project management, Hermes :
https://web.archive.org/web/20190605035517/http://www.hermes.admin.ch:80/onlinepublikation/index.xhtml
In this method, the project is divided into 4 phases:
– Initialization
– Design
– Production
– Deployment
A very interesting point is that the project’s actual start begins only when the initialization is complete.
https://www.hermes.admin.ch/onlinepublikation/index.xhtml?element=supportingmaterial_phasen_beschreibung.html
In this method, all analyzes, variants of studies, risk analysis, is done in the initialization phase.
This prevents tampering of the project which often leads to obtain hydras that no longer resemble to the initial idea.
Another area where planning is present, the building, it may be better not to change a current realization. For example in the context of a building rent per floor, the final recipient changes during construction, it better to finish the interior, then start a new project for the new tenant rather than adapting the existing .